ComfyUI 中controlnet(comfyui_controlnet_aux)的使用方法
- AICG
- 2025-10-20
- 13热度
- 0评论
ControlNet是一个强大的控制网络,允许用户在 ControlNet 图像生成过程中引入额外的条件(如边缘图、深度图、姿势关键点等),从而实现对图像结构和内容的精准控制
常用的 ControlNet 控制类型
| 控制类型 | 主要用途 | 典型预处理器/模型示例 |
|---|---|---|
| 线条控制 (Canny, Lineart) | 依据线稿生成图像,适合结构精确的创作,如产品设计、插画上色。 | Canny细致线预处理器 + control_v11p_sd15_canny 模型 |
| 姿态控制 (OpenPose) | 控制生成人物的身体、手部及面部姿态。 | OpenPose预处理器 + control_v11p_sd15_openpose 模型 |
| 深度控制 (Depth) | 根据深度信息生成具有正确空间感和透视关系的图像。 | MiDaS Depth预处理器 + control_v11p_sd15_depth 模型 |
| 语义分割 (Segment) | 根据色彩分区(每种颜色代表特定物体类别)控制生成内容,常用于场景设计。 | UniFormer Segmentor 等 |
| 风格与色彩 (Shuffle) | 迁移参考图的色彩风格或进行重新上色。 | 通常无需预处理器,直接使用参考图 |
在ComfyUI 中使用 ControlNet
- ControlNet加载器:用于加载具体的ControlNet模型(如Canny、OpenPose等)。需要注意的是,ControlNet模型必须与使用的基础模型版本(如SD1.5或SDXL)匹配
- 预处理器:负责将用户提供的参考图像转换为ControlNet模型可以理解的控制条件(例如,将一张人物照片通过OpenPose预处理器提取出骨骼姿态)。常用的预处理器插件是ComfyUI ControlNet Auxiliary Preprocessors(ComfyUI_controlnet_aux)
- ControlNet应用节点:这是核心节点,它将预处理后的控制条件、ControlNet模型以及文本提示词(正面/负面)整合起来,生成新的条件信号传递给采样器(如K采样器)。
- 强度:控制ControlNet对生成结果的影响程度,值越高越严格遵循参考图
- 开始时间/结束时间:决定ControlNet在生成过程的哪个时间步开始和结束引导,允许进行更精细的控制。
ControlNet 实用技巧与注意事项
- 使用多个ControlNet:你可以将多个
ControlNet应用节点串联起来,同时应用不同的控制条件(如同时控制姿态和深度),以获得更复杂的效果。对于更简洁的工作流,可以考虑使用ControlNet堆节点来管理多个ControlNet输入。 - 参数调整:合理设置
强度和开始/结束时间至关重要。例如,降低强度或让ControlNet在生成后期退出,可以给AI模型更多自由发挥的空间,避免生成结果过于呆板。 - 完美像素模式:通过
完美像素节点可以处理参考图与生成图尺寸不一致的问题,它通过计算合适的缩放比例来保持图像比例,避免变形。 - 资源准备:使用前需确保已下载所需的ControlNet模型文件(通常为
.pth或.safetensors格式),并将其放置在ComfyUI的models/controlnet目录下。预处理器的模型文件通常在首次使用时自动下载。
在comfyui的ControlNet示例
准备
安装节点:comfyui_controlnet_aux
添加模型:
xinsir/ControlNet++: All-in-one ControlNet (ProMax model) models\controlnet
2b_nier_automata.safetensors models\loras
animagineXLV31_v31.safetensors models\checkpoints流程图截图中含有工作流
comfyui_controlnet_aux 节点
ComfyUI的comfyui_controlnet_aux是一个功能强大的扩展插件,它集成了多种图像预处理节点,能够将普通图像转换为ControlNet模型可识别的控制图(如线稿、深度图、人体姿态图等),从而实现对AI图像生成过程的精准控制
核心节点:AIO Aux Preprocessor
为了简化操作,插件提供了一个非常实用的AIO Aux Preprocessor(全功能辅助预处理器)节点。这个“全能”节点将绝大部分预处理器功能整合在一起,你只需在节点的preprocessor参数下拉菜单中选择需要的预处理类型(例如LineArtPreprocessor用于标准线稿提取,OpenPosePreprocessor用于人体姿态估计),并设置好输出图像的resolution(分辨率),即可将输入的普通图片转换为对应的控制图。
它的优势在于极大简化了工作流,无需为每种控制类型寻找单独的节点。缺点是它无法调整某些预处理器独有的高级参数(如Canny的边缘阈值)。若需精细控制,则需使用具体的预处理器节点(如CannyEdgePreprocessor)。
预处理器节点分类
除了AIO节点,插件也提供了众多独立的专用预处理器节点,主要可分为以下几类:
- 线条与边缘提取器:用于从图像中提取轮廓线稿。
CannyEdgePreprocessor:生成清晰的硬边缘线稿。LineArtPreprocessor/AnimeLineArtPreprocessor:分别用于提取写实风格和动漫风格的线稿。ScribblePreprocessor:生成手绘风格的草图。
- 深度与法线估计器:用于感知图像中的空间关系。
MiDaS-DepthMapPreprocessor/DepthAnythingV2Preprocessor:估算图像的深度信息,生成深度图。MiDaS-NormalMapPreprocessor:估算物体表面法线,生成法线图。
- 姿态与面部估计器:用于识别图像中人或动物的姿态和面部关键点。
OpenPosePreprocessor:估计人体骨骼关节点。DWPosePreprocessor:提供比OpenPose更详细的手部和面部关键点。MediaPipe-FaceMeshPreprocessor:检测人脸网格。
- 语义分割器:将图像按物体类别分割成不同颜色的区域。
OneFormer-ADE20KPreprocessor:对自然场景图像进行分割。OneFormer-COCO-SemSegPreprocessor:对常见物体(COCO数据集)进行分割。
基本工作流程
在ComfyUI中结合comfyui_controlnet_aux使用ControlNet的基本工作流程如下:
- 加载图像:使用
Load Image节点加载你的参考图。 - 预处理图像:将加载的图像连接到
AIO Aux Preprocessor节点的图像输入口,并选择所需的预处理器类型。 - 加载ControlNet模型:使用
Load ControlNet Model节点,加载与所选预处理器对应的ControlNet模型(例如,使用CannyEdgePreprocessor,就需要加载control_v11p_sd15_canny这样的Canny模型)。 - 应用ControlNet:使用
Apply ControlNet节点。将第2步中AIO Aux Preprocessor输出的图像连接到该节点的image输入口;将第3步加载的ControlNet模型连接到control_net输入口;将文本编码器(CLIP Text Encode)输出的正面和负面提示词条件分别连接到positive和negative输入口。 - 生成图像:将
Apply ControlNet节点输出的条件连接到K采样器(KSampler)的相应条件输入口,即可开始生成受控的图像。
在Apply ControlNet节点中,可以通过调整strength(强度)参数来控制ControlNet对生成结果的影响程度,以及start_percent和end_percent来控制ControlNet在生成过程中的介入时机。
线条控制 (Canny)
ControlNet 的线条控制 (Canny边缘检测) 会从输入图像(照片、线稿、草图等)中提取出清晰的边缘线条(如物体的轮廓、部件的边界、场景的空间关系等),ControlNet 则会强制生成模型 “沿着这些线条” 绘制细节,确保生成图像的整体结构与线条高度一致。Canny 控制的核心是 “约束结构,放开细节”:
- 线条定义的宏观结构(如形状、位置、比例)会被严格遵守;
- 线条未定义的细节内容(如颜色、纹理、材质)则由 AI 根据提示词自由发挥。
例:若输入一张人物线稿(只有轮廓线条),Canny 控制会让 AI 生成的人物严格符合线稿的肢体姿态、发型轮廓、服装剪裁等,不会出现 “线条画的是站姿,生成结果却是坐姿” 的偏差。
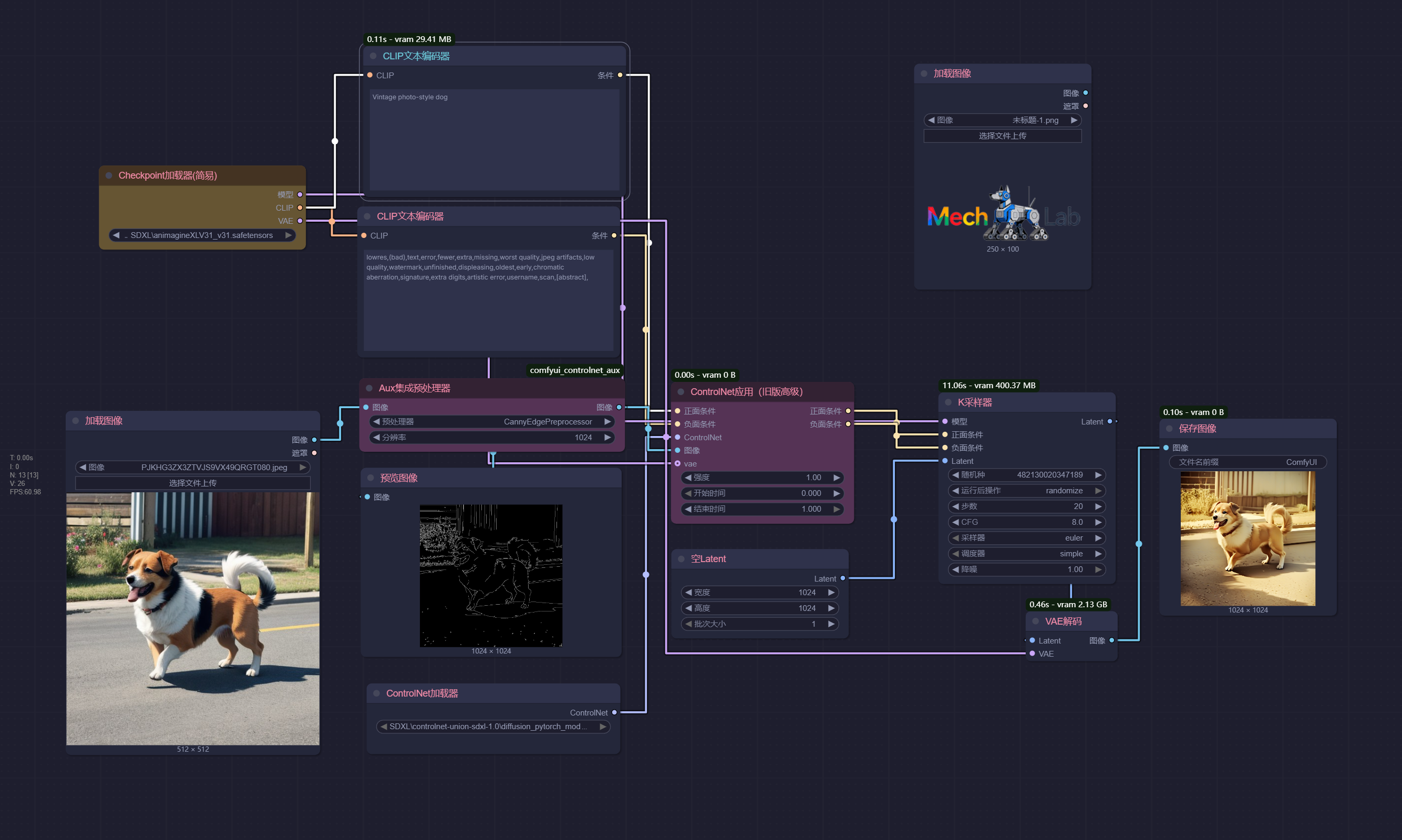
| 原始图片 | 景深分析 | 老照片风格 | 动漫风格 | 赛博风格 |
|---|---|---|---|---|
 |  |  |  |  |
姿态控制 (OpenPose)
ControlNet 的ControlNet 的姿态控制(OpenPose)核心功能是通过检测人体的骨骼关键点(如关节、肢体位置),精准约束 AI 生成图像中人物的姿态、动作和肢体结构。
- 精准锁定人体姿态,避免 “动作跑偏”
- 支持复杂场景:多人、动态动作也能精准控制
- 降低创作门槛:无需专业绘画,轻松实现复杂动作
- 平衡 “姿态固定” 与 “细节创作”
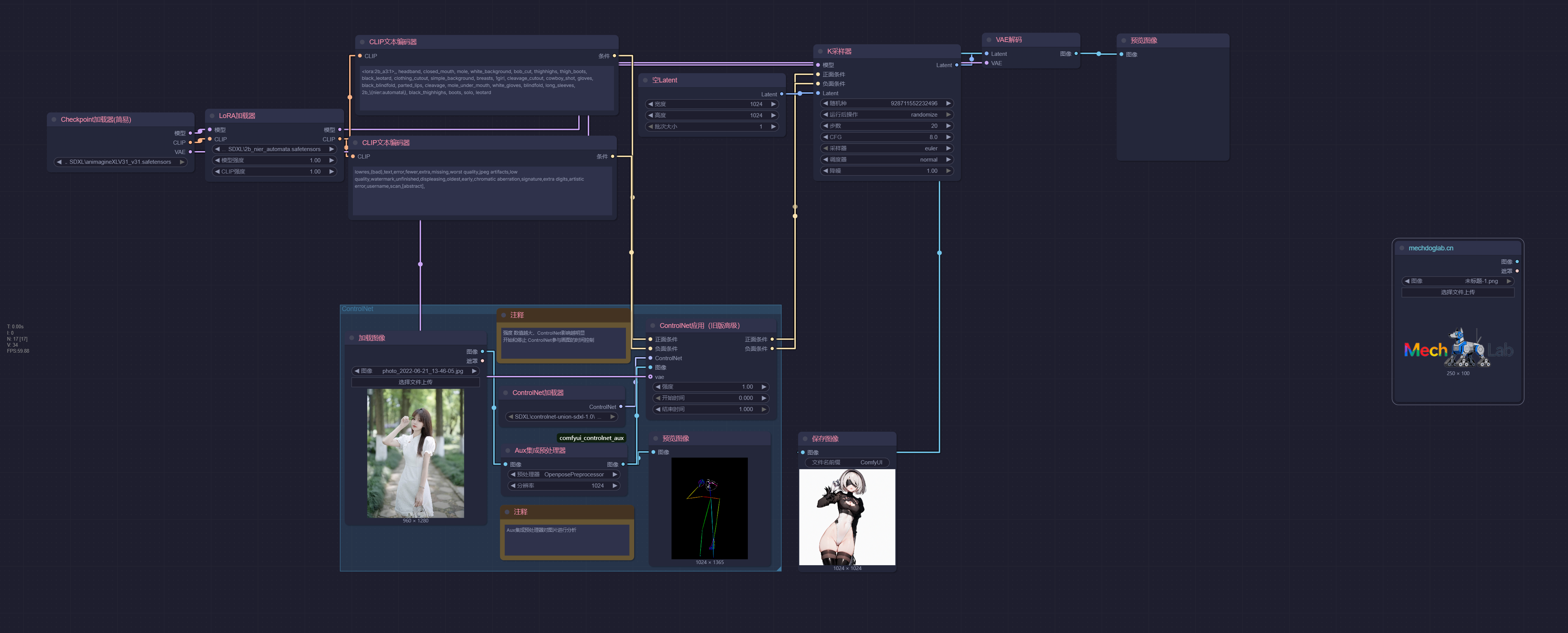
| 原始图片 | 姿势分析 | 输出图片 |
|---|---|---|
 |  |  |
深度控制 (Depth)
ControlNet 的深度控制(Depth)核心功能是通过 “深度图”(表示物体远近关系的灰度图)约束 AI 生成图像的空间层次感、立体感和透视关系,让生成结果严格遵循 “谁在前、谁在后、距离多远” 的物理空间逻辑,解决纯文本生成时 “物体叠层混乱、透视错误、缺乏立体感” 的问题。
- 精准锁定 “空间层次”,避免物体 “前后错位”
- 控制 “透视关系”,确保场景符合真实物理规律
- 支持 “复杂场景的深度一致性”,多人 / 多物空间关系可控
- “锁定空间,放开细节”,平衡可控性与创造性
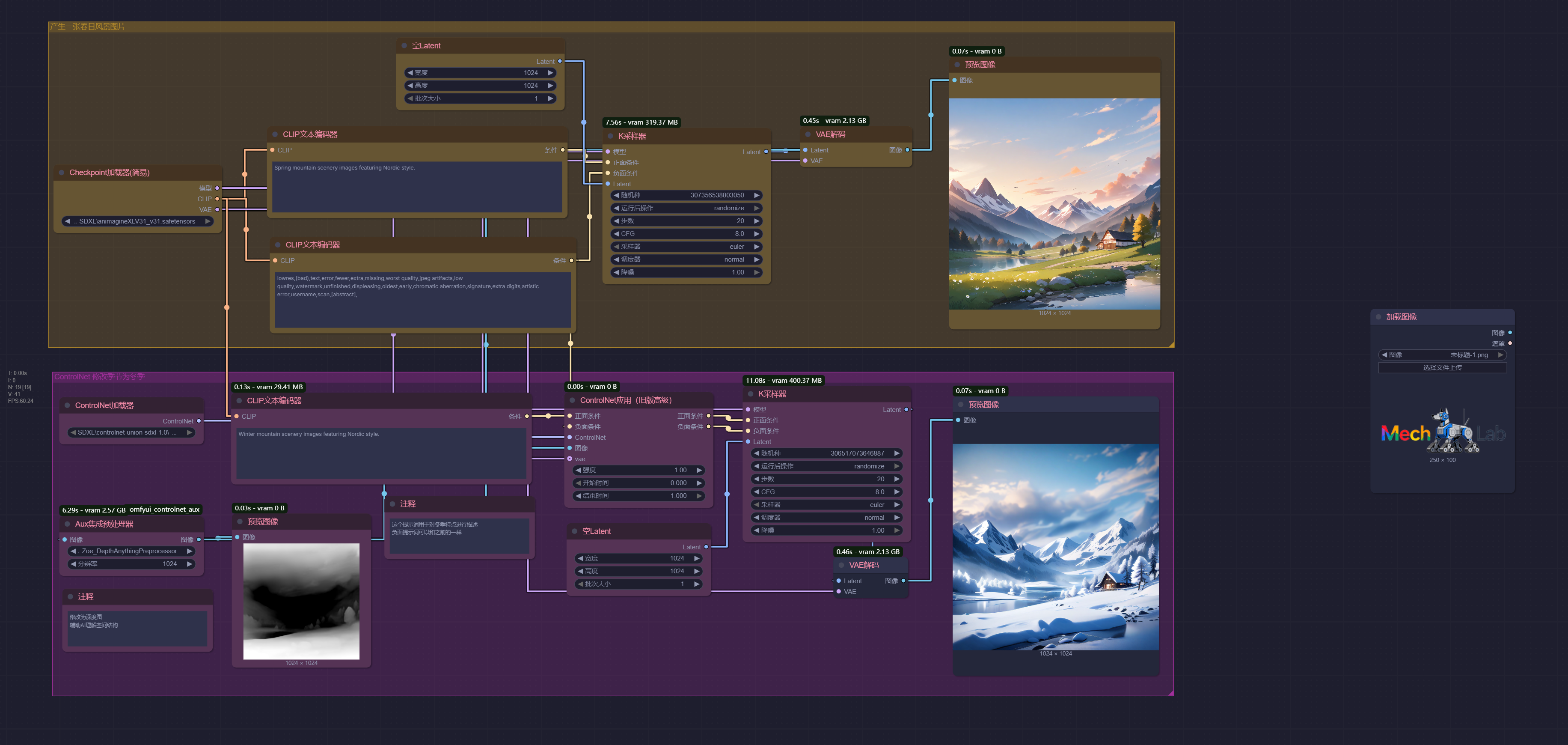
| 原始图片 | 景深分析 | 输出图片 |
|---|---|---|
 |  |  |
语义分割 (Segment)
ControlNet 的ControlNet 的语义分割(Segment)控制功能,核心是通过对图像进行 “类别区域划分”(即语义分割图),约束 AI 生成图像中不同物体的类别、位置和区域分布,让生成结果严格遵循 “哪些区域属于什么物体” 的逻辑,解决纯文本生成时 “物体错位、类别混淆” 的问题。
- 精准锁定 “区域类别”,避免物体 “张冠李戴”
- 控制复杂场景的 “布局结构”,确保物体关系合理
- 灵活调整 “外观细节”,但不改变 “区域布局”
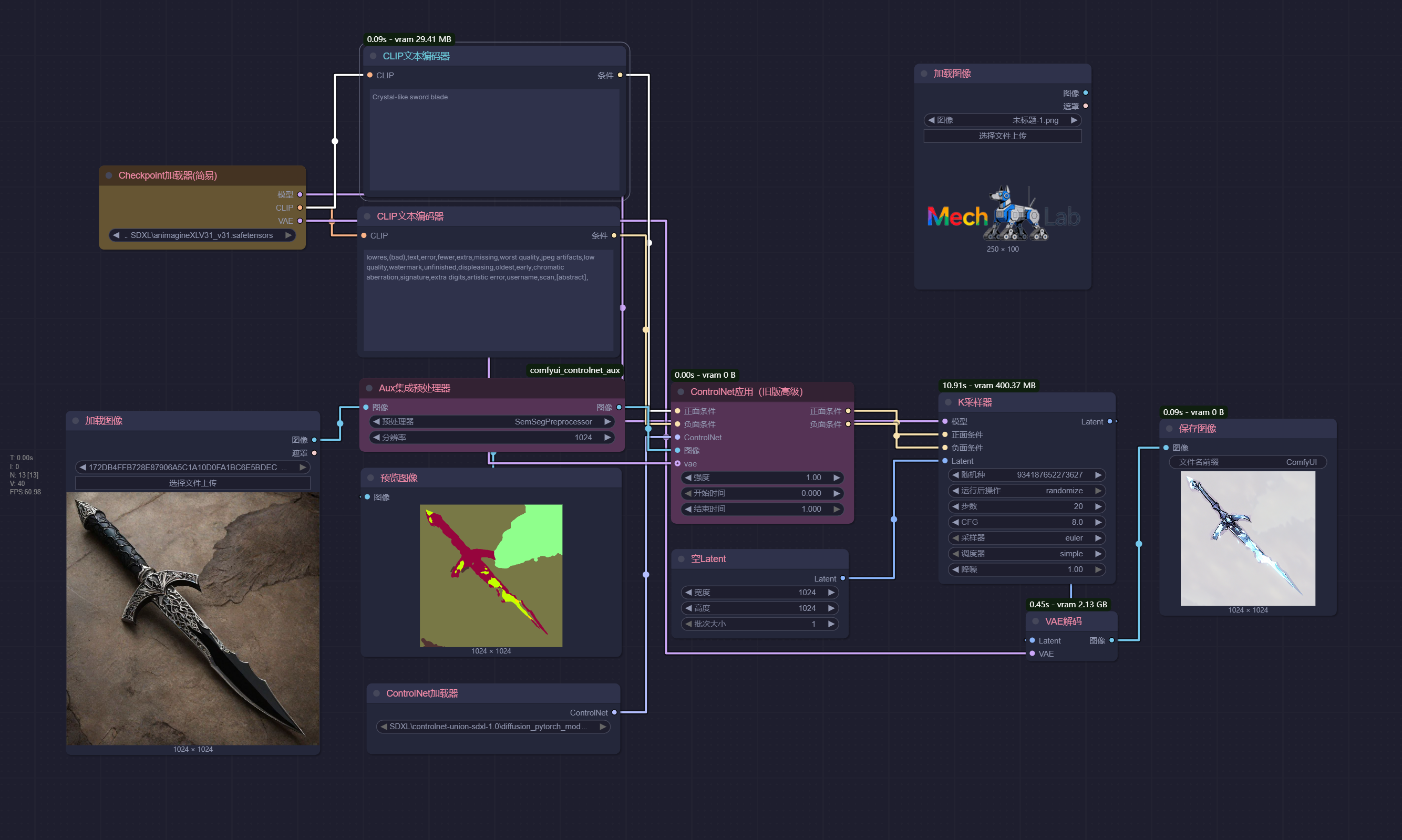
| 原始图片 | 图片分析 | 输出图片 |
|---|---|---|
 | 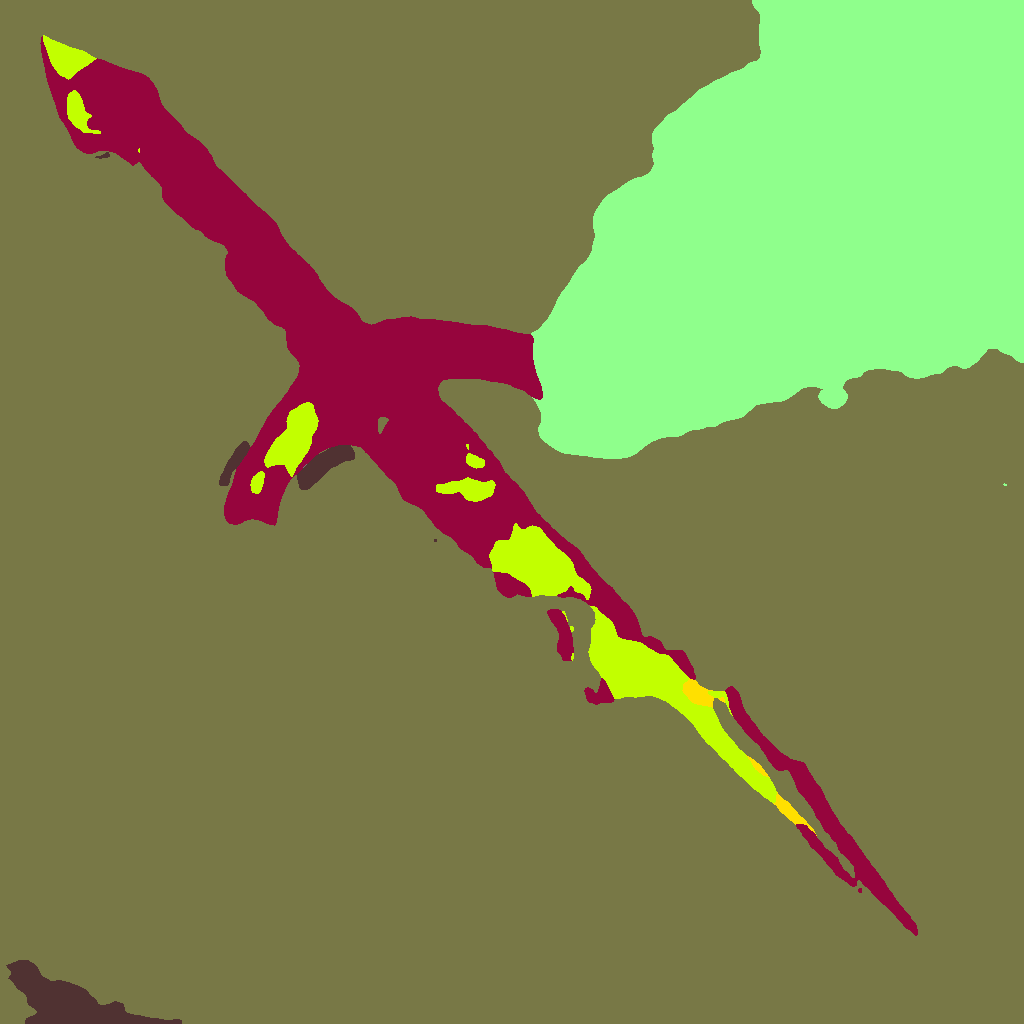 |  |
风格重构 (Shuffle)
ControlNet 中的Shuffle的核心是 “保留结构,替换风格特征”,通过对原图像的 “风格特征” 进行打乱重组,让生成图像在严格遵循原图像结构(如人物姿态、物体轮廓、场景布局)的基础上,呈现全新的风格(如从写实到卡通、从照片到油画)。
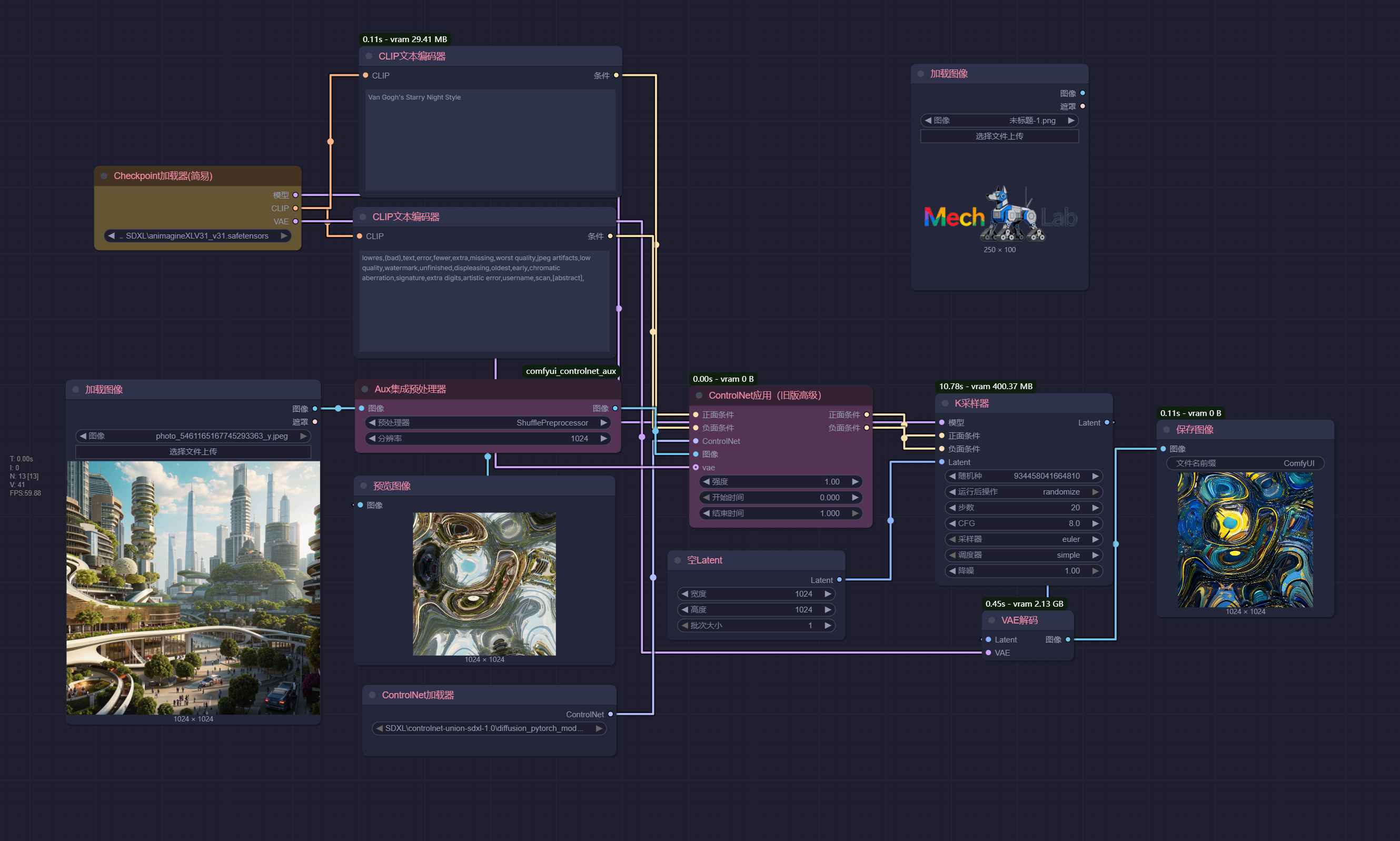
Van Gogh's Starry Night Style 梵高的星空风格
| 原始图片 | 图片重构 | 输出图片 |
|---|---|---|
 |  |  |