免费在Colab上使用unsloth微调大语言模型
- AI Tool
- 29天前
- 11热度
- 0评论
支持免费的模型
Github项目地址 https://github.com/unslothai/unsloth
| 模型 | 性能 | 内存使用 |
|---|---|---|
| gpt-oss (20B) | 1.5x faster | 70% less |
| Qwen3 (14B) | 2x faster | 70% less |
| DeepSeek-OCR (3B) | 1.5x faster | 30% less |
| gpt-oss (20B): GRPO | 2x faster | 80% less |
| Qwen3-VL (8B): GSPO | 1.5x faster | 80% less |
| Qwen3-VL (8B) | 2x faster | 50% less |
| Gemma 3 (270M) | 1.7x faster | 60% less |
| Gemma 3n (4B) | 1.5x faster | 50% less |
| Llama 3.1 (8B) | 2x faster | 70% less |
| Orpheus-TTS (3B) | 1.5x faster | 50% less |
为什么要微调大语言模型
- 适配特定任务:通用模型可能不擅长细分任务(如专业翻译、代码生成、客服对话),微调能让模型聚焦任务逻辑,大幅提升准确率和效率。
- 补充领域知识:通用模型缺乏垂直领域(医疗、法律、金融)的专属知识,微调可注入行业数据,让回答更专业、无偏差。
- 对齐使用偏好:统一输出风格(如口语化、正式报告、简洁指令)、遵守定制规则(如避免敏感内容、固定回复格式),贴合实际使用场景。
微调模型过程
注意:微调后的 LoRA 模型不能直接在 Ollama 中使用,需先合并权重、转换格式为 Ollama 支持的 GGUF 格式,再导入使用。
步骤1
创建一个新的Colab

步骤2
用unsloth库中的FastLanguageModel类来加载和使用语言模型
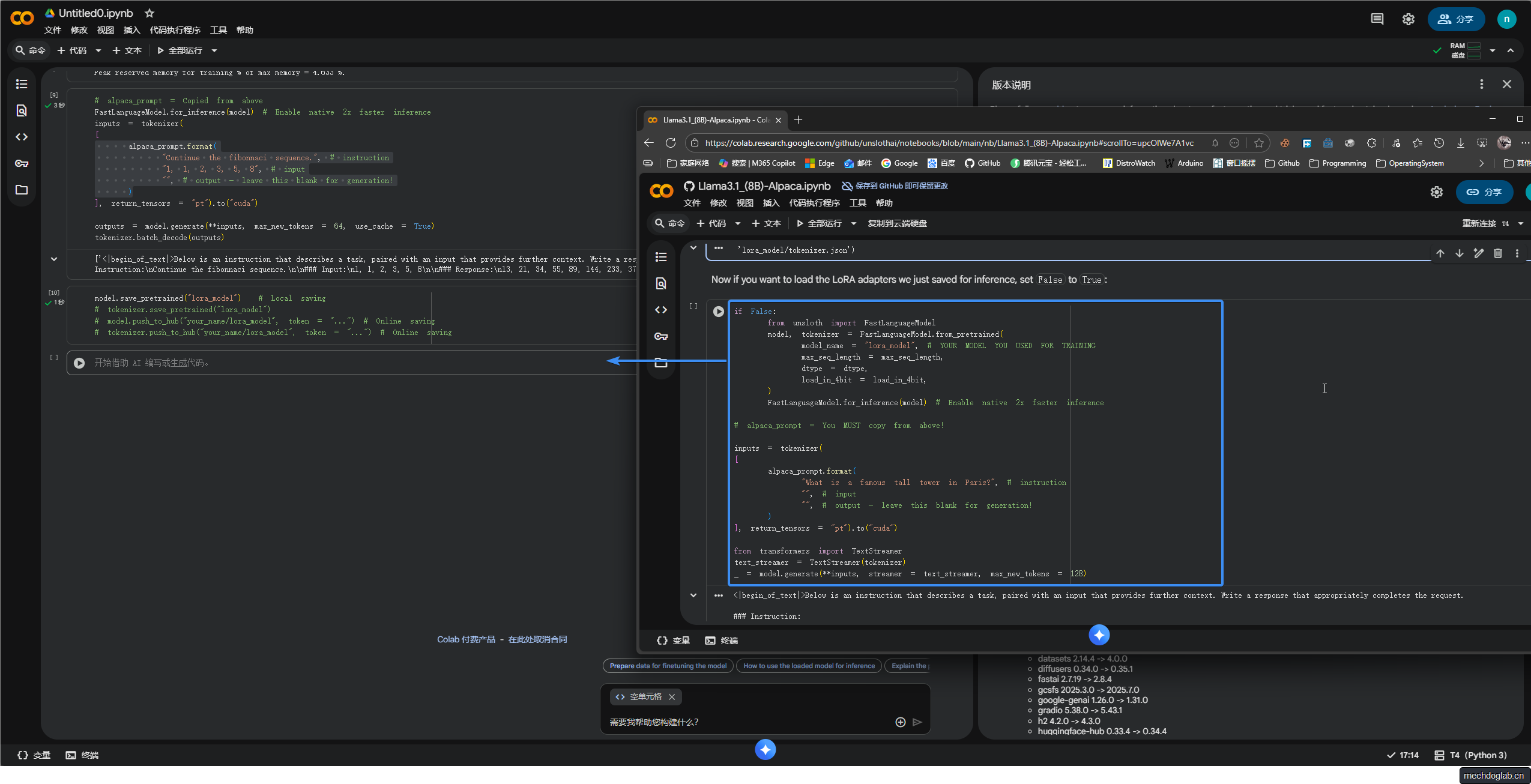
步骤3
使用unsloth库从预训练的4位量化模型列表中加载unsloth/llama-3-8b-bnb-4bit模型
并自动支持不同数据类型和序列长度的调整以减少内存使用并提高下载速度
model_name = "unsloth/Meta-Llama-3.1-8B" 表示模型名称和版本
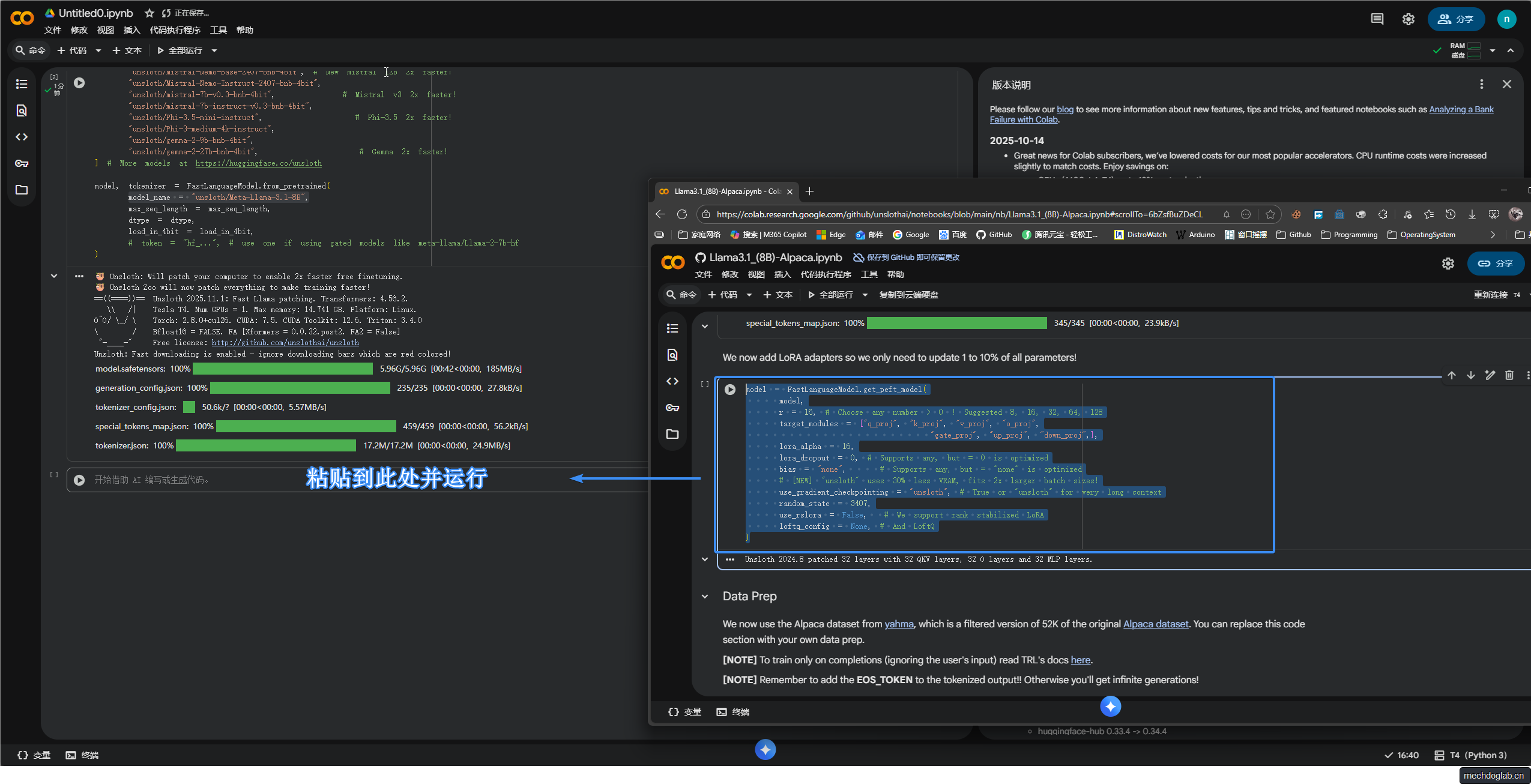
步骤4
对目标模型进行参数扩展技术的配置,增强原有 FastLanguageModel模型的功能,
优化内存使用并提升处理长文本序列的能力
步骤5
加载一个名为yahma/alpaca-cleaned的训练数据集,
并通过定义的formatting_prompts_func函数,
格式化每个样本以包括指令、上下文输入和预期输出,
末尾加上结束符号以防生成文本无限制地延续
加载数据集
dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
数据集内容
https://huggingface.co/datasets/yahma/alpaca-cleaned
数据集格式
"instruction":"Summarize the given article in 200 Words.",
"input": "https://www.bbc.com/news/world-51461830",
"output": "The recent protests in Belarus are part of a growing wave of discontent against the rule of Alexander Lukashenko, who has led the country since 1994. Demonstrations against his government have been ongoing since August, and come in the wake of an election widely seen as rigged. As police and security forces have cracked down on protesters, the movement has only grown, with hundreds of thousands of people taking to the streets to call for new leadership. Human rights activists have accused the government of using extreme violence in order prosecute protesters, leading to an international outcry and sanctions from the European Union. As the situation in Belarus continues to unfold, the international community is monitoring the situation closely - hoping for a peaceful resolution, while also standing firm against the oppressive tactics employed by the Belarusian state."
"instruction": "Classify the following shape according to simple geometry.",
"input": "<Picture Attached>",
"output": "Triangle"
"instruction": "Given a recent news article, write a headline for it.",
"input": "https://www.news.example.com/article-1",
"output": "\"NASA Launches a Mars 2020 Mission to Search for Signs of Ancient Life\""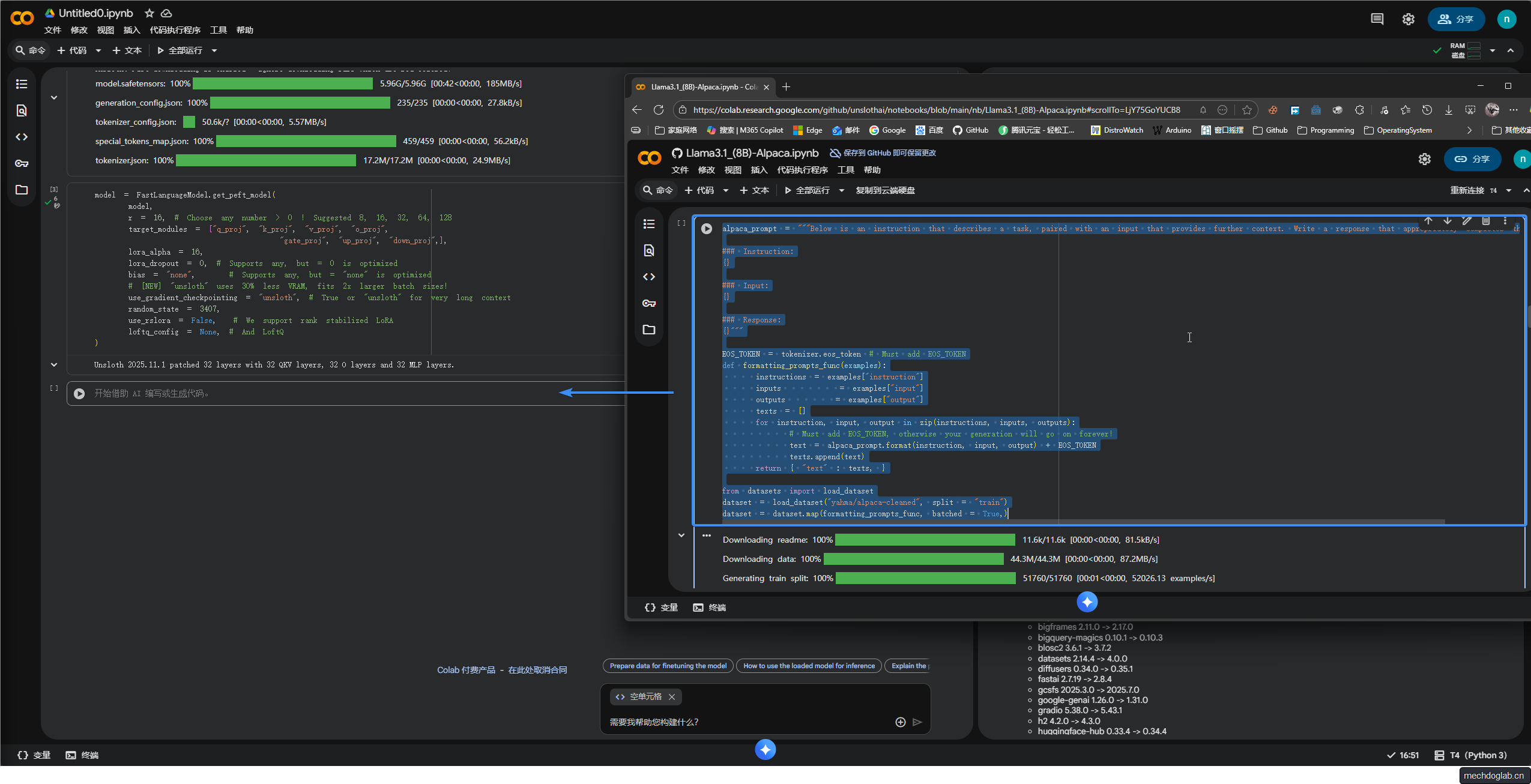
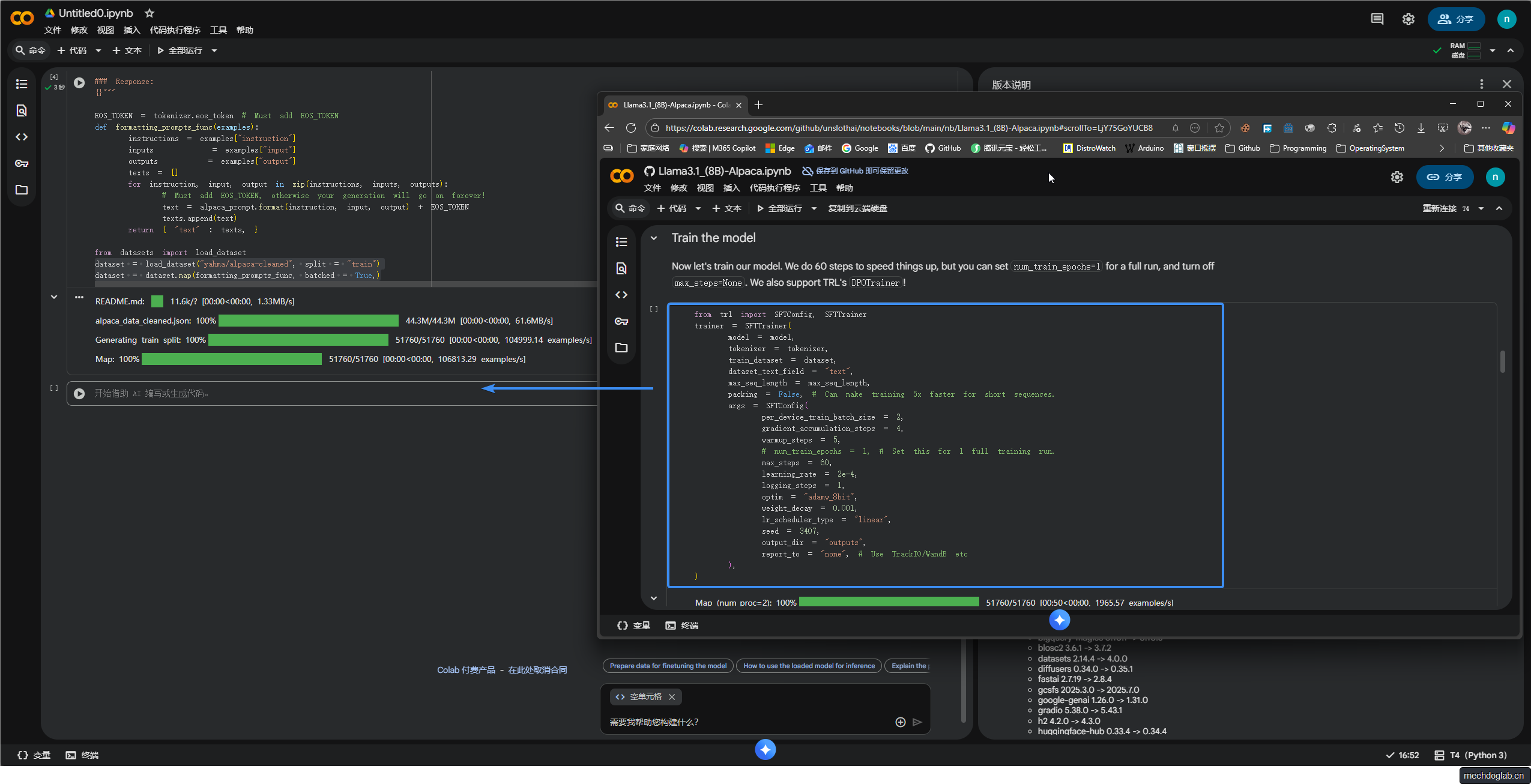
步骤6
设置训练环境
利用SFTTrainer
和一系列的TrainingArguments
来配置和执行自然语言模型的微调
使用了指定的数据集、优化器、学习率调度器
同时考虑到了处理器类型以优化训练效率
max_steps = 60, 最大步数60步
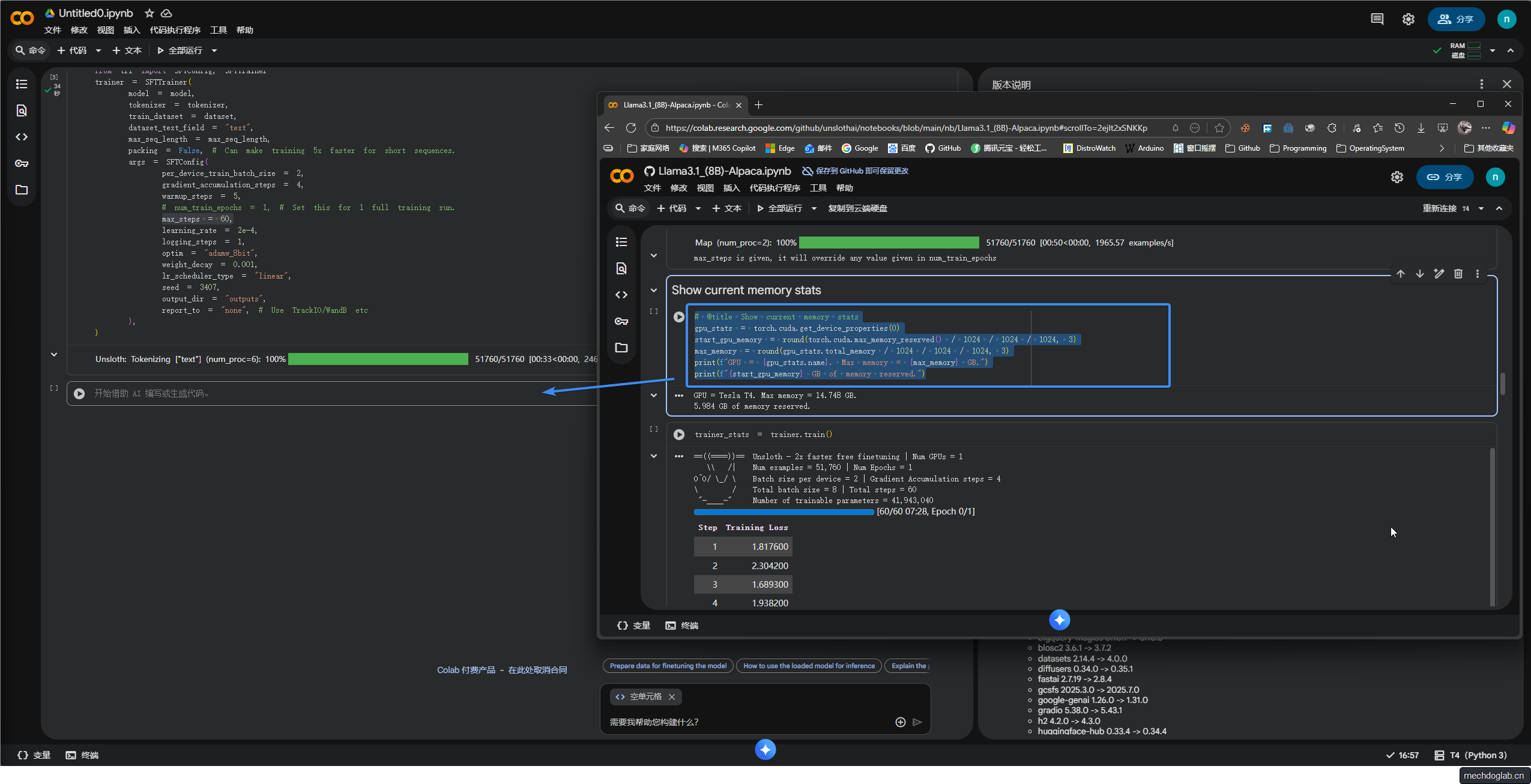
步骤7
设置训练环境
显示当前GPU的名称和最大内存容量
同时报告已预留的GPU内存使用量
帮助用户监控和管理GPU资源使用情况
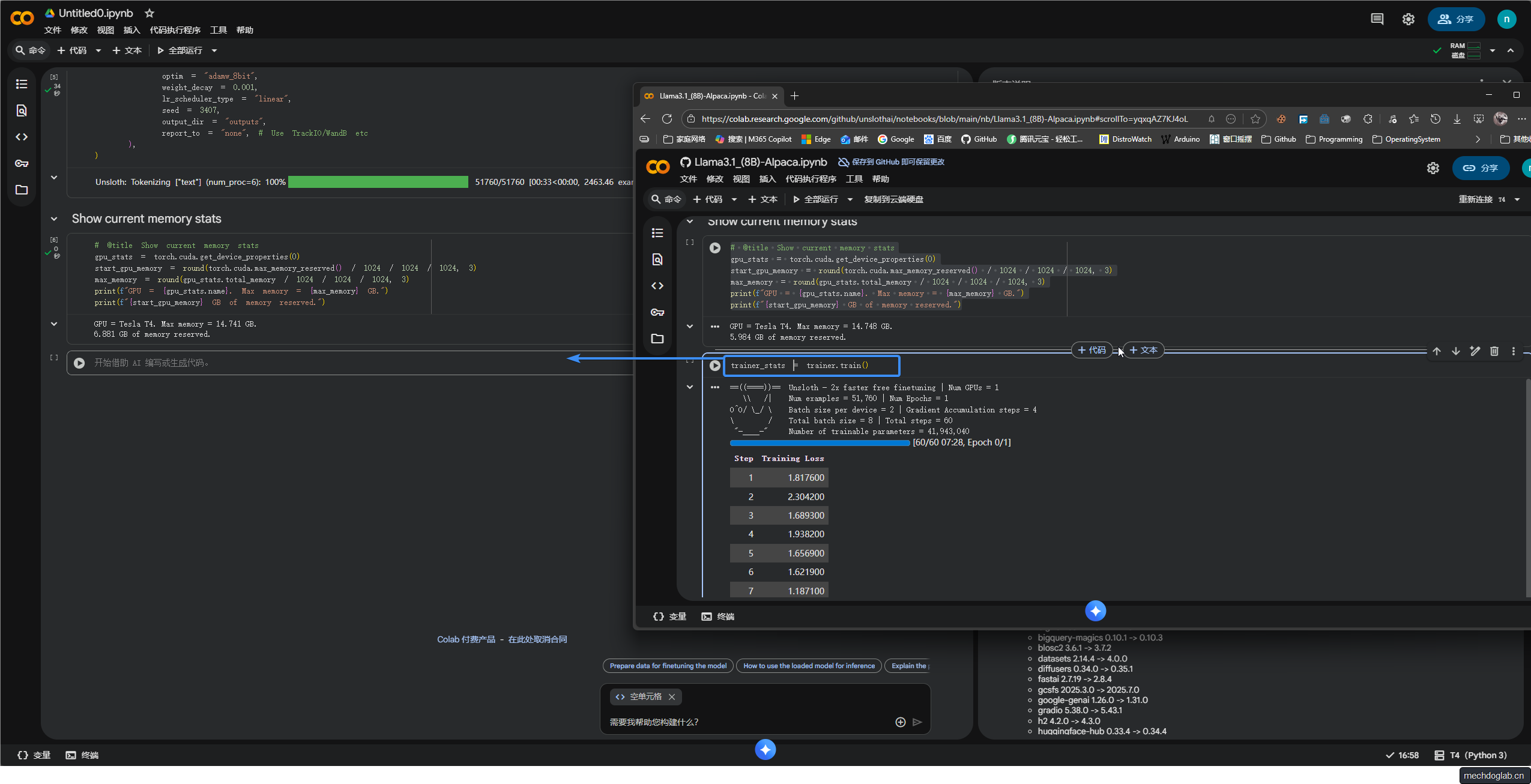
步骤8(训练)
启动之前配置的trainer对象的训练过程
并将训练过程中收集的统计信息
存储在trainer_stats变量中
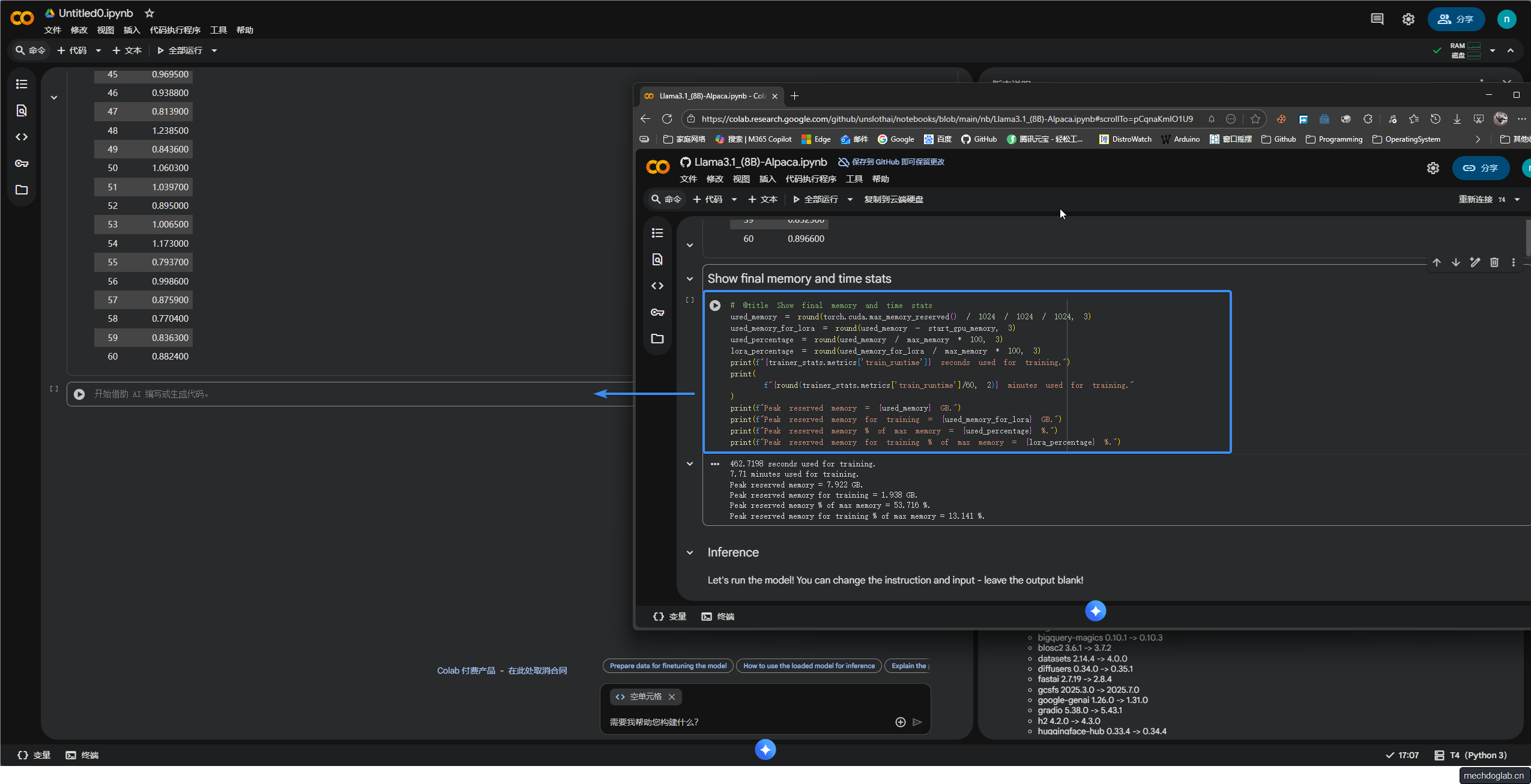
步骤9
显示最终内存和时间统计数据
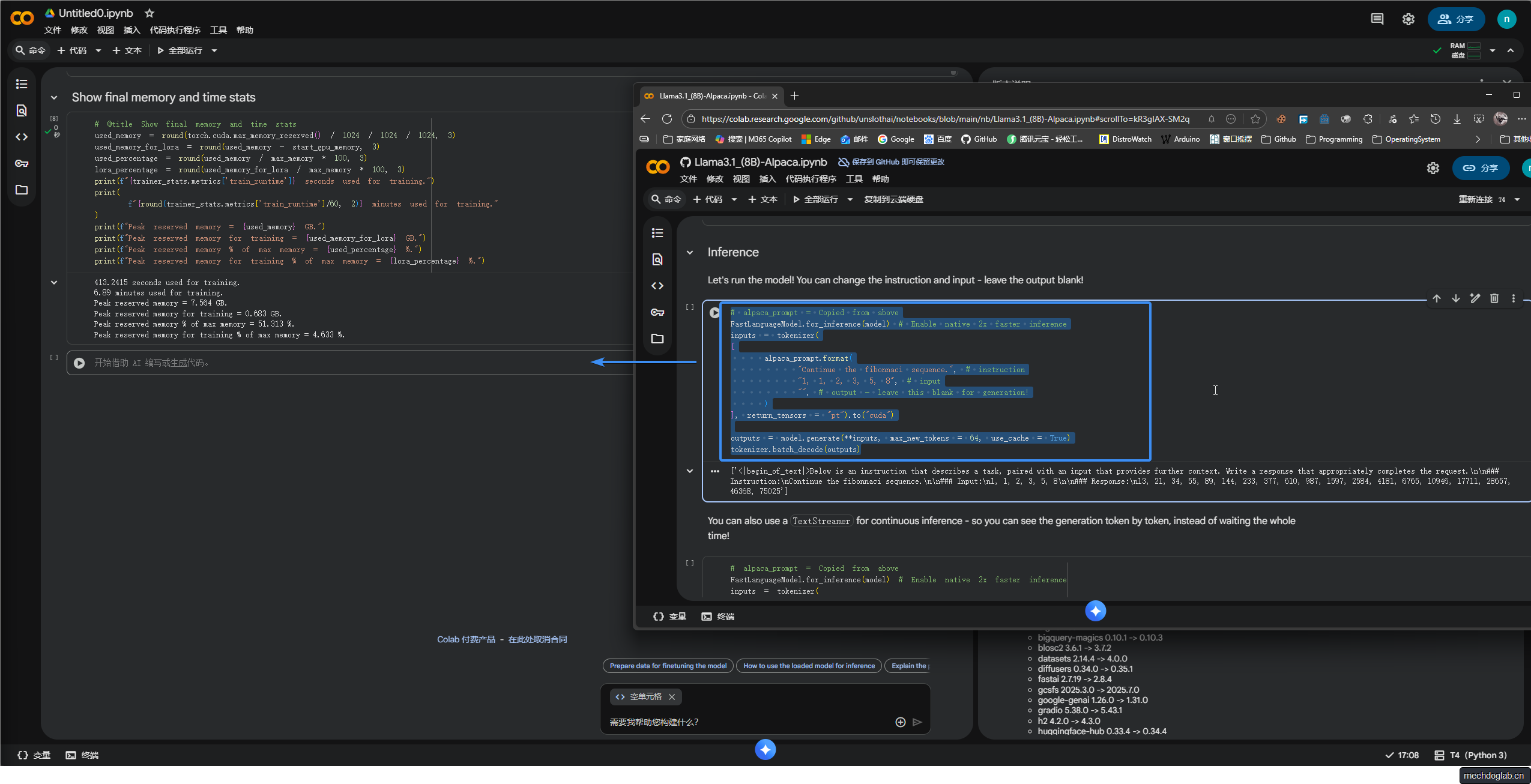
步骤10(运行模型)
通过格式化并准备输入文本
然后利用配置为更快推理的FastLanguageModel模型生成文本
并使用tokenizer将生成的输出解码为可读文本
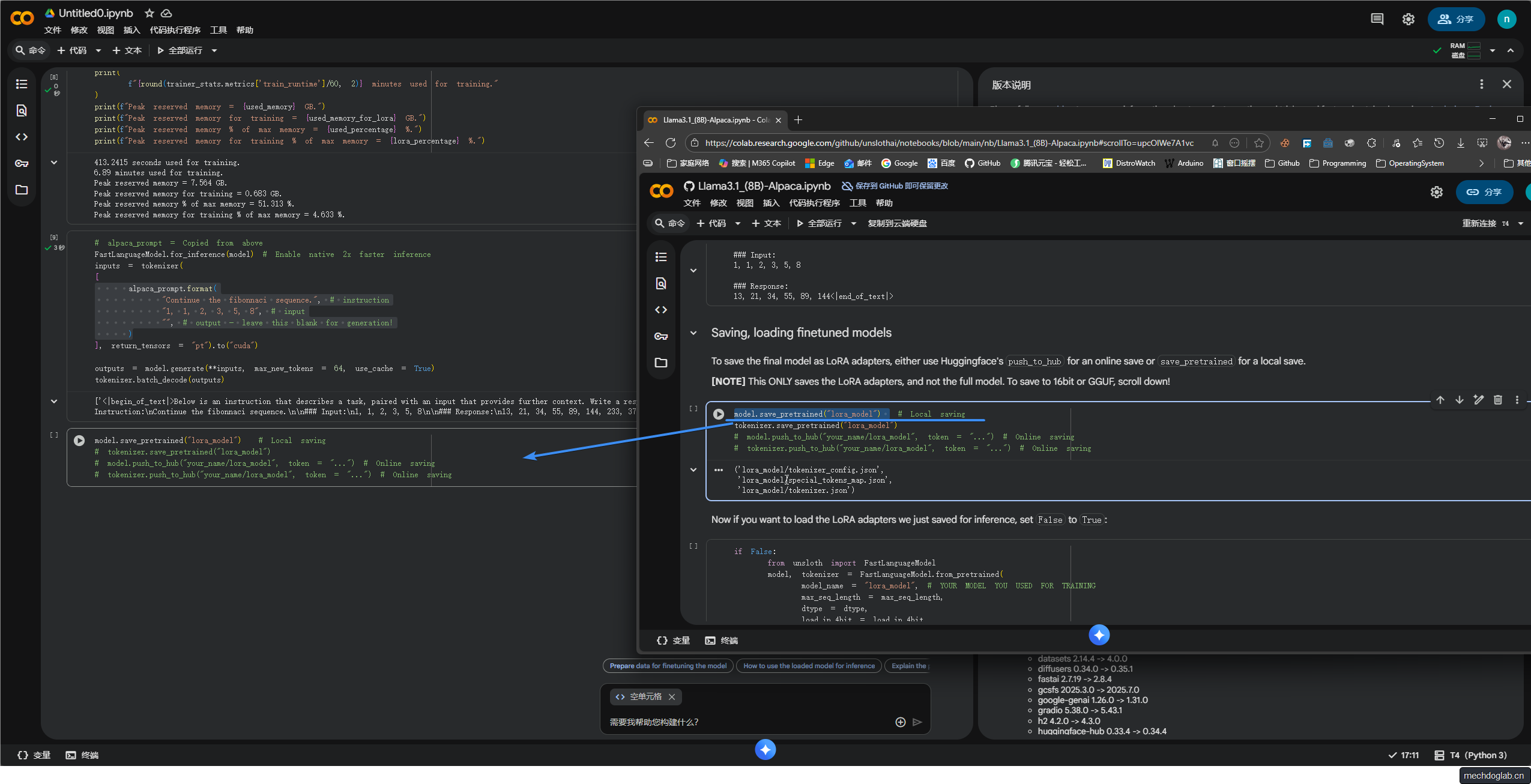
步骤11
保存微调模型
步骤12
格式化一个文本生成任务的输入
使用已训练的模型生成对问题的回答
并将生成的文本从模型输出中解码显示
输出
### Instruction:
What is a famous tall tower in Paris? 巴黎最出名的塔是什么塔
### Input:
### Response:
One of the most famous tall towers in Paris is the Eiffel Tower. This iconic structure was built in 1889 for the World's Fair and stands at a height of 324 meters (1,063 feet). It is the tallest building in Paris and the second most visited paid monument in the world. The Eiffel Tower is a symbol of Paris and is known for its beautiful views of the city and the surrounding area.<|end_of_text|>