Dify通过Firecrawl获取网页内容并生成知识库
- AI Tool
- 29天前
- 12热度
- 0评论
准备工作
- Docker本地部署Firecrawl
- 使用本地的ollama支持的Embedding 模型或者API提供的Embedding 模型
Dify中Firecrawl插件设置
安装Firecrawl
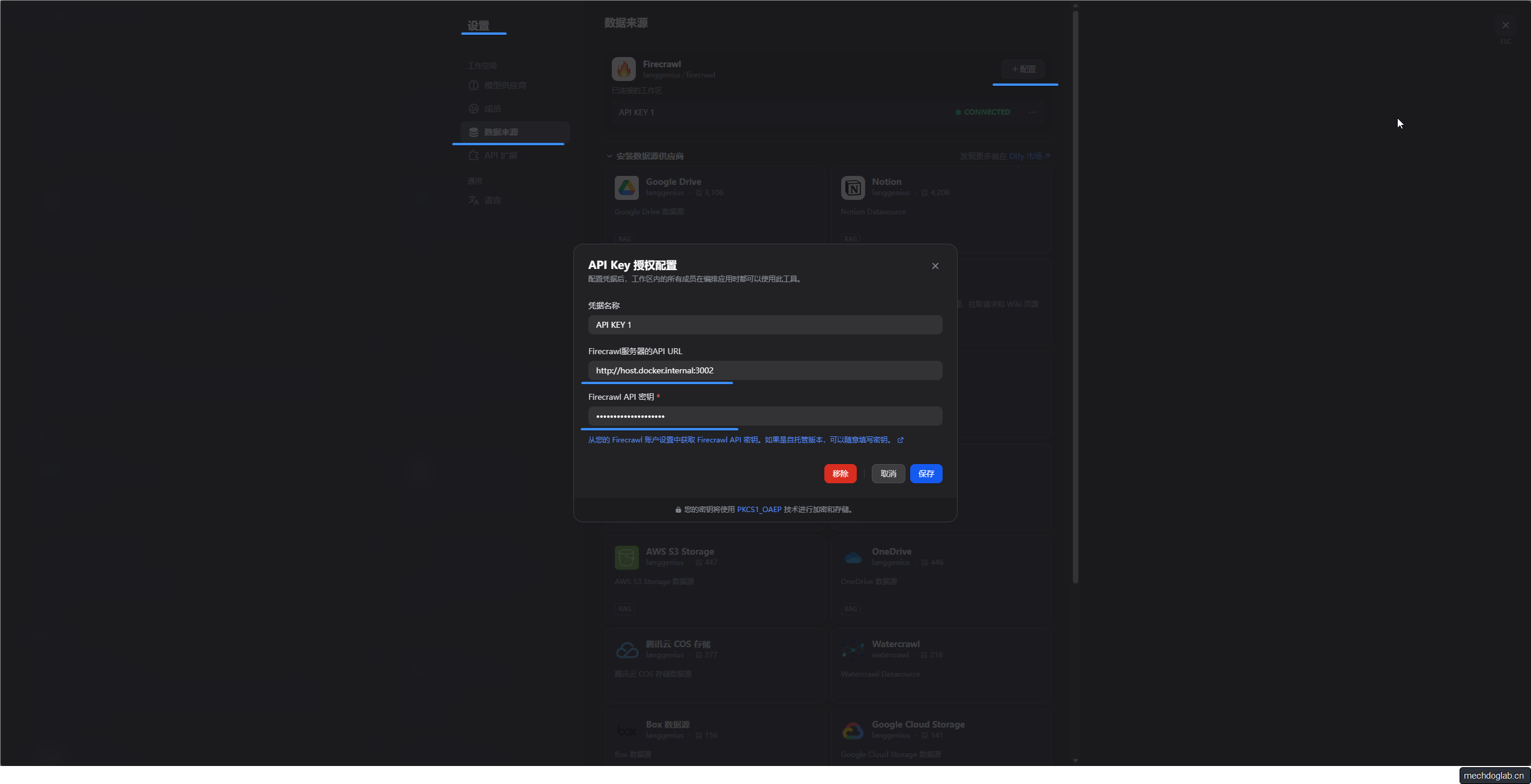
Firecrawl的API Key 授权配置
- 路径:设置 - 数据来源 - Firecrawl设置
- Firecrawl服务器的API URL(本地部署):http://host.docker.internal:3002
- Firecrawl API 密钥:(你本地部署时设置的值)
- 完成后点击保存,Firecrawl应该处于connected状态
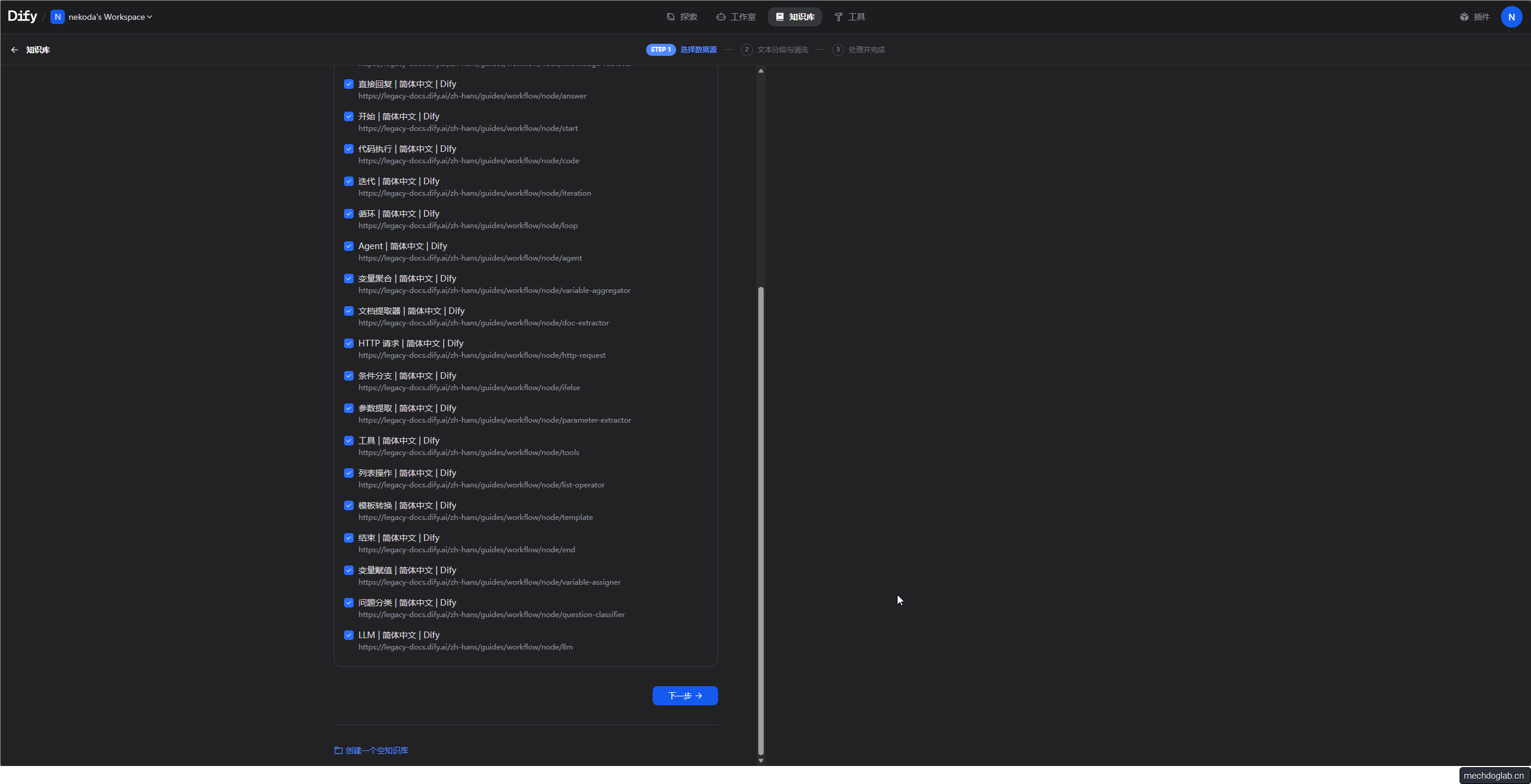
内容爬取
- 创建知识库,数据来源选择同步自WEB站点
- 工具选择“Firecrawl”
- 输入要获取的站点URL,这里为了演示输入的是dify官方文档 (https://legacy-docs.dify.ai/zh-hans/guides/workflow/node)
- 设置最大深度和限制数量

- 获取完成后点击下一步
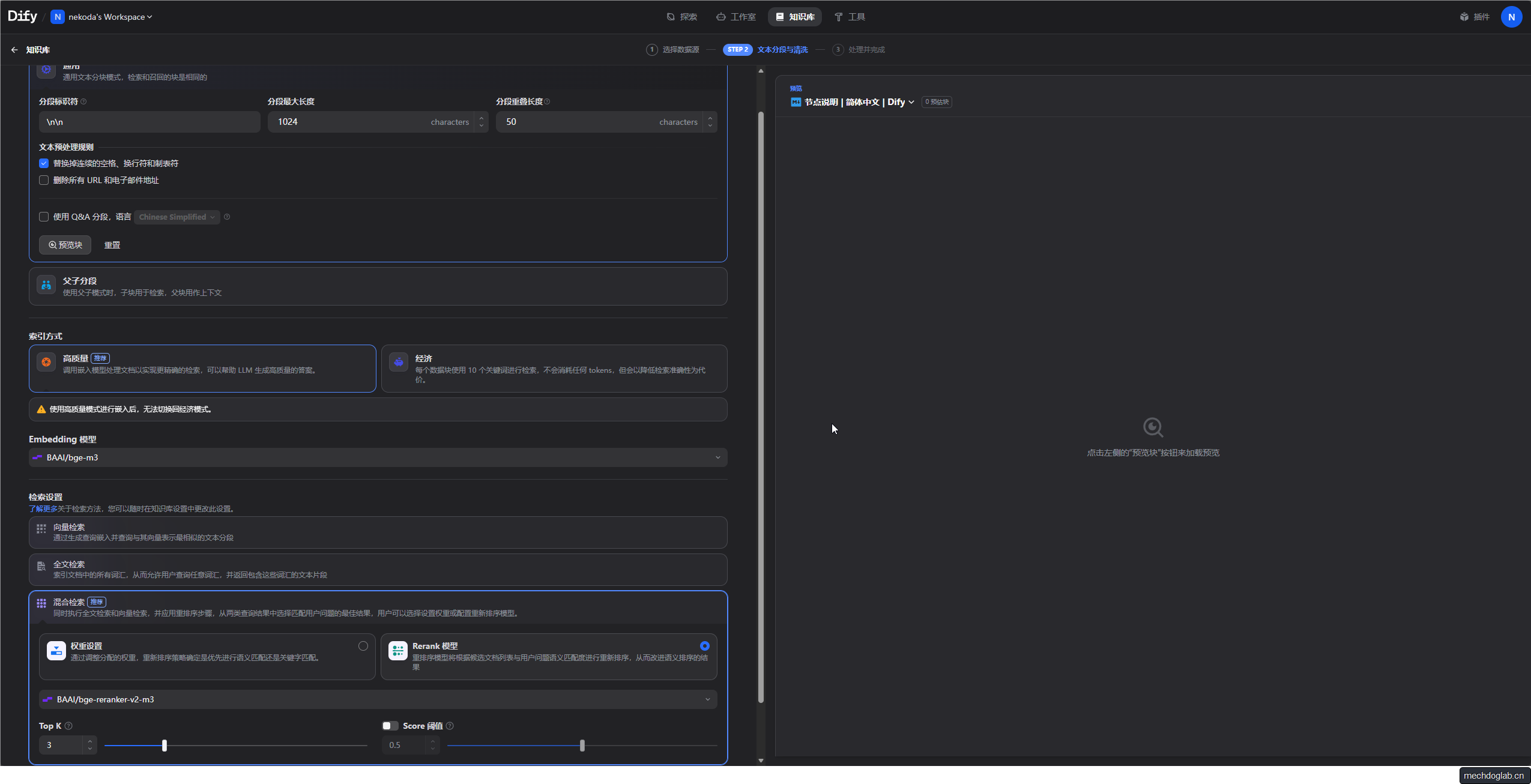
知识库设置
- Embedding 模型
- 这里我选择的是硅基流动提供的免费模型
- 索引方式
- 高质量
- 检索设置
- 向量检索:基于语义理解的智能搜索
向量检索通过嵌入模型(Embedding Model)将文本(如用户查询和知识库文档)转换为高维向量(即一组数字),并计算这些向量之间的相似度(如余弦相似度)来找到语义上最匹配的内容。例如,当用户查询“苹果的营养价值”时,即使知识库中的文档使用的是“苹果的营养成分”这类措辞,向量检索也能因理解两者的语义关联而准确召回相关内容。其优势在于能深度理解自然语言,处理同义词、复杂语义或模糊查询,但需要较多的计算资源,且效果依赖于嵌入模型的质量。它特别适用于需要深层语义理解的场景,如科研文献检索、法律条文查询或智能问答。 - 全文检索:基于关键词匹配的精准搜索
全文检索直接依赖关键词匹配,通过倒排索引快速定位包含用户查询中特定词汇的文本片段。例如,搜索“Python3.9”时,它能精准返回包含该确切术语的文档,但无法理解“Python编程语言”等语义关联性表达。这种方式检索速度快、实现简单,但对自然语言的语义理解能力弱,可能因一词多义或同义词问题导致召回结果不准确或遗漏信息。全文检索适用于关键词明确、需要快速定位的场景,如新闻检索、商品搜索或日志分析。 - 混合检索:结合语义与关键词的优化方案
混合检索同时执行向量检索和全文检索,并对两者的初步结果进行整合与重排序,以兼顾语义相关性和关键词匹配精度。Dify推荐使用该方式,因其能通过权重设置(调整语义和关键词检索的贡献比例)或重排序模型(Rerank)进一步优化结果。例如,在处理“智能手表的健康功能”这类复杂查询时,向量检索捕捉“健康监测”的语义,全文检索匹配“智能手表”关键词,混合检索则能综合筛选最相关答案。虽然配置和管理相对复杂,但它在准确性和召回率上通常优于单一模式,尤其适用于企业知识库、智能客服等复杂业务场景。
- 向量检索:基于语义理解的智能搜索
| 检索方式 | 核心原理 | 优势 | 局限性 | 典型场景 |
|---|---|---|---|---|
| 向量检索 | 文本向量化后计算语义相似度 | 语义理解强,处理模糊查询 | 计算资源消耗大,依赖模型质量 | 智能问答、学术研究 |
| 全文检索 | 关键词匹配与倒排索引 | 速度快,适合精确术语查找 | 无法理解语义,易受词汇差异影响 | 新闻搜索、商品检索 |
| 混合检索 | 结合两者并重排序结果 | 准确性与召回率高,适应复杂需求 | 配置复杂,需维护多种索引 | 企业知识管理、专业咨询 |
- dify 知识库中的Top K 和 Score阈值
- Top K 参数的含义与设置
- Top K 定义了检索系统返回的与用户查询最相关的文本片段(chunks)的最大数量。例如,设置Top K=5时,系统会返回相似度得分最高的5个文本块。其作用包括:
- 控制结果数量:较小的Top K值(如3)会使检索结果更精准,适合问答或资源有限的场景;较大的Top K值(如10)能召回更多内容,适合调研或模糊查询,但可能引入噪声。
- 默认值:Dify中Top K的默认值通常为3。
- 设置位置:在知识库的“检索设置”界面中直接输入数值即可配置。
- Score 阈值的含义与设置
- Score阈值(相似度阈值)规定了文本片段被召回所需的最低相似度分数,范围在0到1之间,分数越高表示与查询的语义相关性越强。例如,阈值设为0.7时,仅保留相似度得分≥0.7的片段。其作用包括:
- 过滤低质量结果:较高的Score阈值(如0.8)提升结果相关性,但可能导致遗漏信息;较低的阈值(如0.5)召回更全面,但可能包含不相关内容。
- 默认值:默认通常为0.5或关闭状态。
- 设置位置:在“检索设置”界面中输入阈值数值。
- 参数设置操作步骤
- 进入检索设置:在知识库详情页,点击“检索设置”或类似选项。
- 修改参数值:
- 在“Top K”字段输入期望返回的最大片段数(如5)。
- 在“Score阈值”字段输入最小相似度分数(如0.6)。
- 保存并测试:保存设置后,使用“召回测试”功能输入样例问题,观察返回片段的相关性和数量,迭代调整参数。
- 调优策略与场景建议
- 高Top K + 低Score阈值(如Top K=10, Score=0.5):适用于信息探索类场景(如市场调研),旨在广泛召回内容,再通过后续处理(如重排序)提炼结果。
- 低Top K + 高Score阈值(如Top K=3, Score=0.8):适合精准问答或资源受限场景(如客服系统),确保结果高度相关,减少大模型处理负担。
- 分阶段调优:先固定Top K(如50),调整Score阈值至满意准确率;再逐步降低Top K以平衡计算成本。
- 启用Rerank模型时:如果配置了重排序模型,Top K和Score阈值主要在Rerank阶段生效,此时可适当提高Top K(如20)让Rerank模型有更多候选进行精排。
- Top K 参数的含义与设置
- 为知识库设置一个方区分的名称并等待所有URL状态为可用
通过Chatflow使用知识库
工作流示例
示例下载:https://pan.baidu.com/s/14-YeB8eNF4nmU3MGs-ekXA?pwd=4pyw 提取码: 4pyw
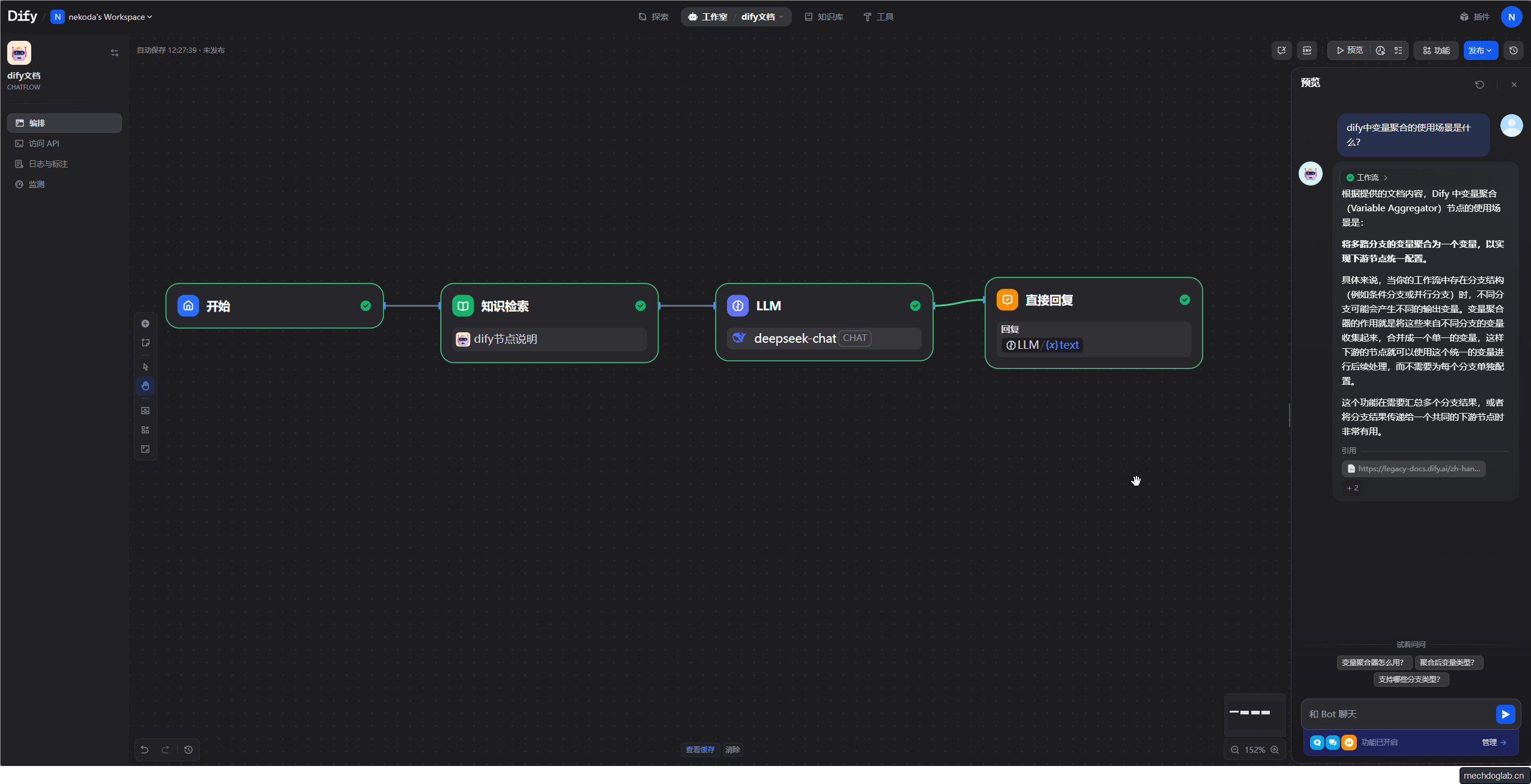
开始节点
- 开始节点保持默认
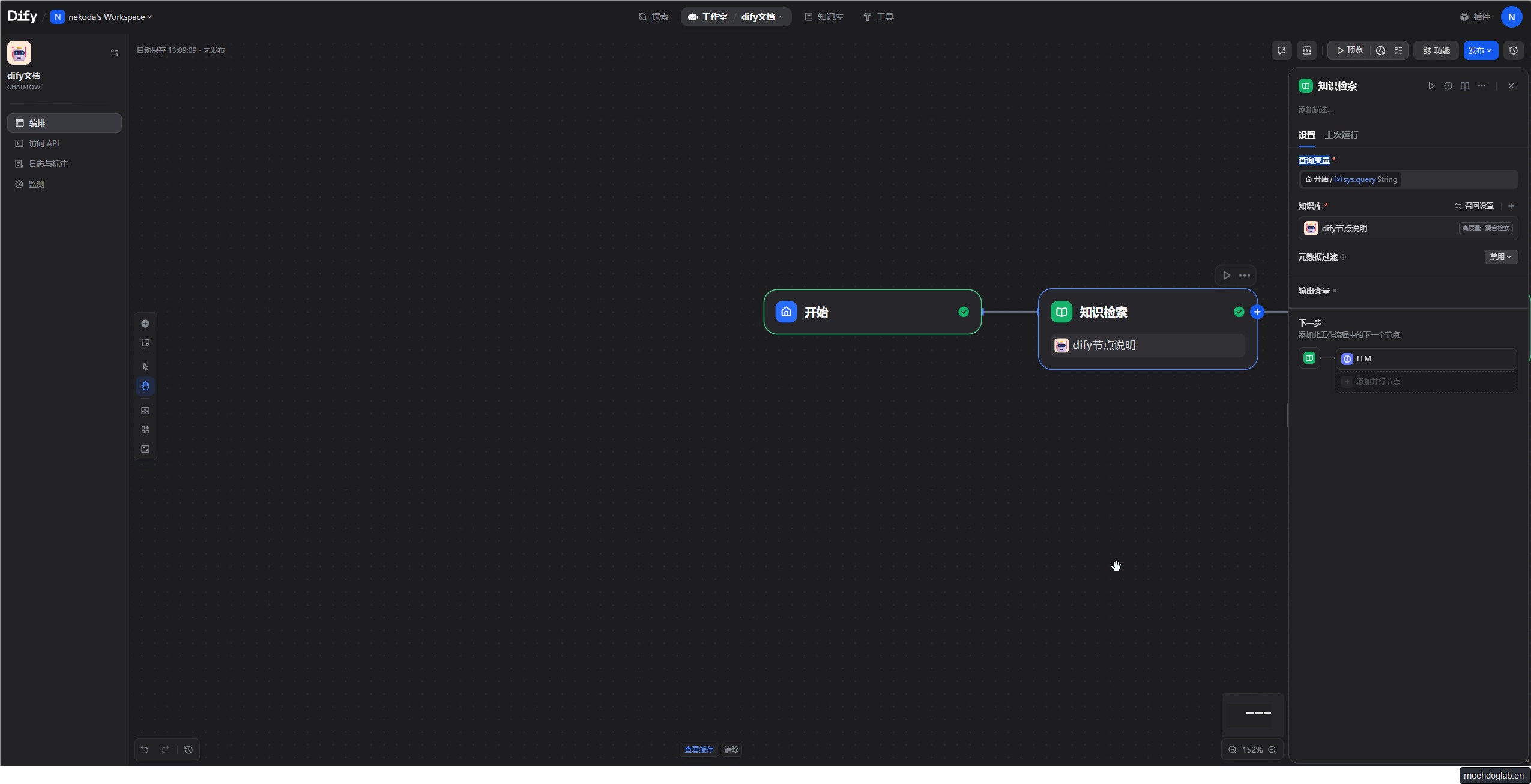
知识检索
- 查询变量来自开始节点的用户输入
- 知识库选择dify节点说明
- (可选)设置知识库的Top K和Score阈值
大语言模型节点
- 模型选择CHAT(我使用deepseek-chat)
- 上下文检索设置为知识检索的输出变量
- 系统提示词
根据下面的提示词结果回答用户的问题
{{#sys.query#}}
---
{{#context#}}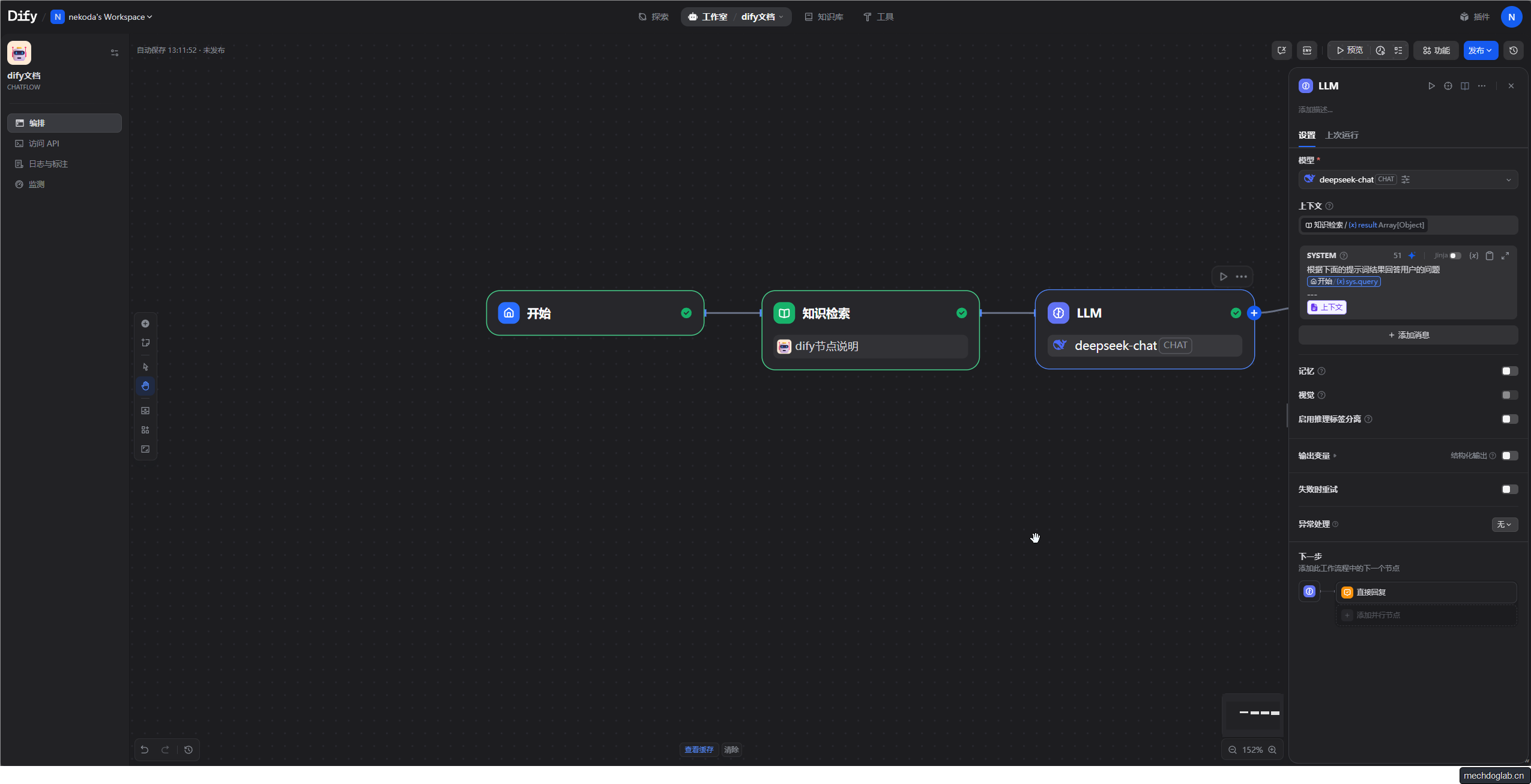
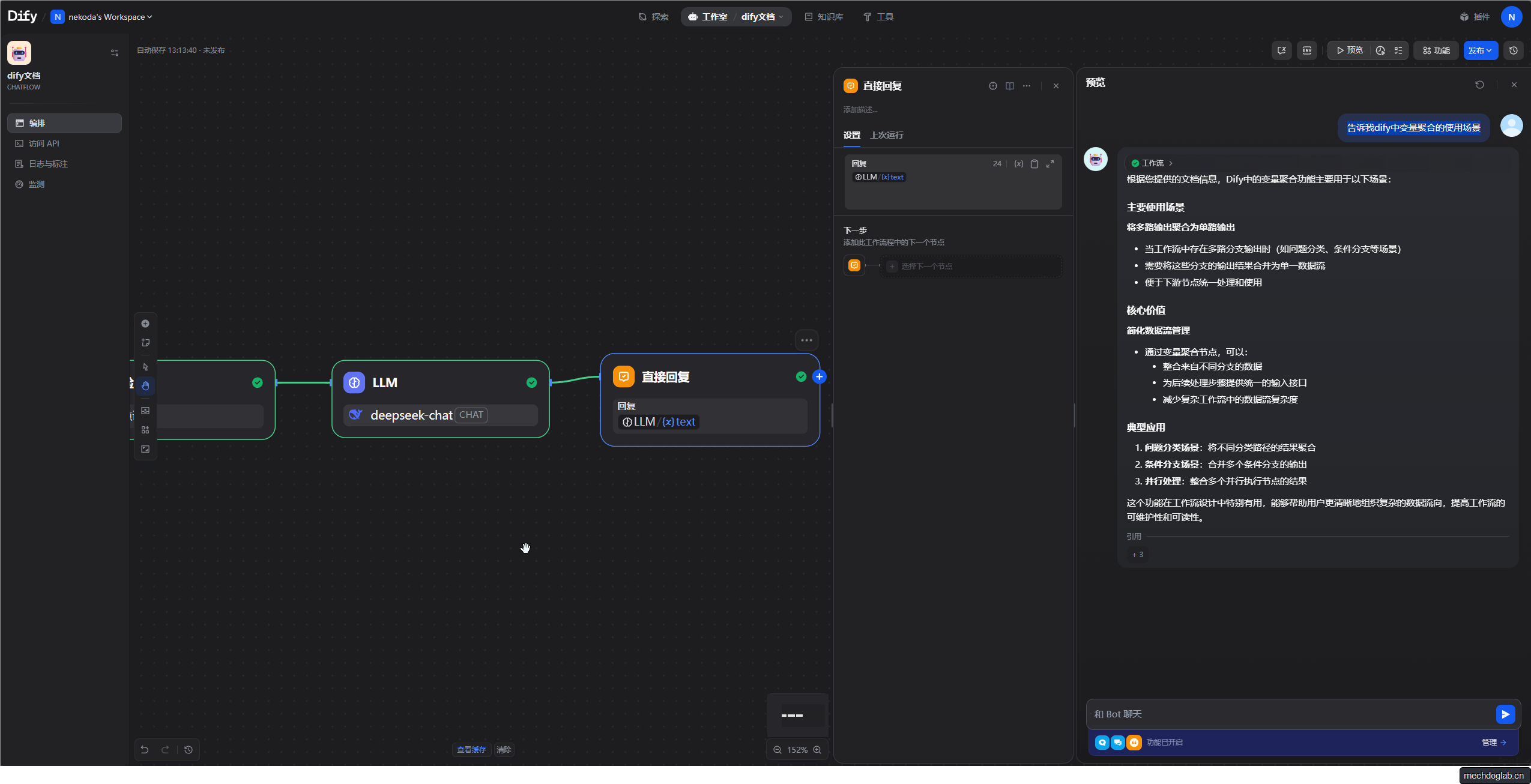
直接回复
- 获取上一步LLM的输出变量
功能测试
- 提问“告诉我dify中变量聚合的使用场景”