ComfyUI中使用InfiniteTalk模型实现口播主持人、虚拟歌手
- AICG
- 2025-10-31
- 23热度
- 0评论
模型加载
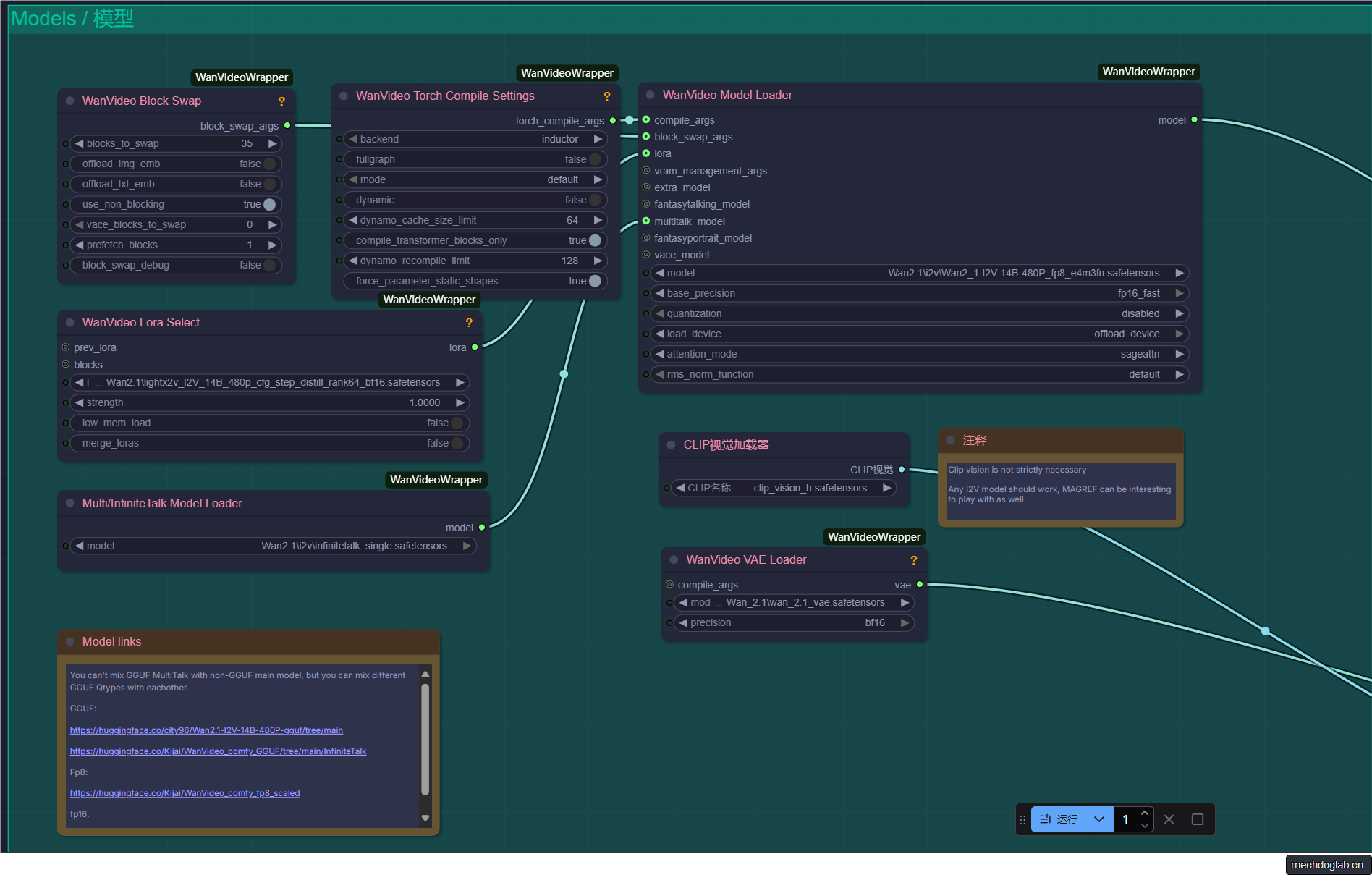
- lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16
- https://pan.baidu.com/s/11_k9iYhwhfZpvAwSZL2CbQ?pwd=jmpk 提取码: jmpk
- infinitetalk_single.safetensors (单人场景)
- https://pan.baidu.com/s/1zwJY-wEzZHSZYwtkcCn1RA 提取码: zpxi
- infinitetalk_multi.safetensors (多人场景)
- https://pan.baidu.com/s/1cVP_ZoD6ekxqXc2eL5uNEA?pwd=5ihn 提取码: 5ihn
- Wan2_1-I2V-14B-480P_fp8_e4m3fn
- https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1-I2V-14B-480P_fp8_e4m3fn.safetensors
- clip_vision_h.safetensors
- https://pan.baidu.com/s/1nKqhDv7IhtlmwefRuKqKVA?pwd=tmtt 提取码: tmtt
- wan_2.1_vae.safetensors
- https://pan.baidu.com/s/1FM-pdOwqh3M7746uzW2NFA?pwd=fjtc 提取码: fjtc
图片输入
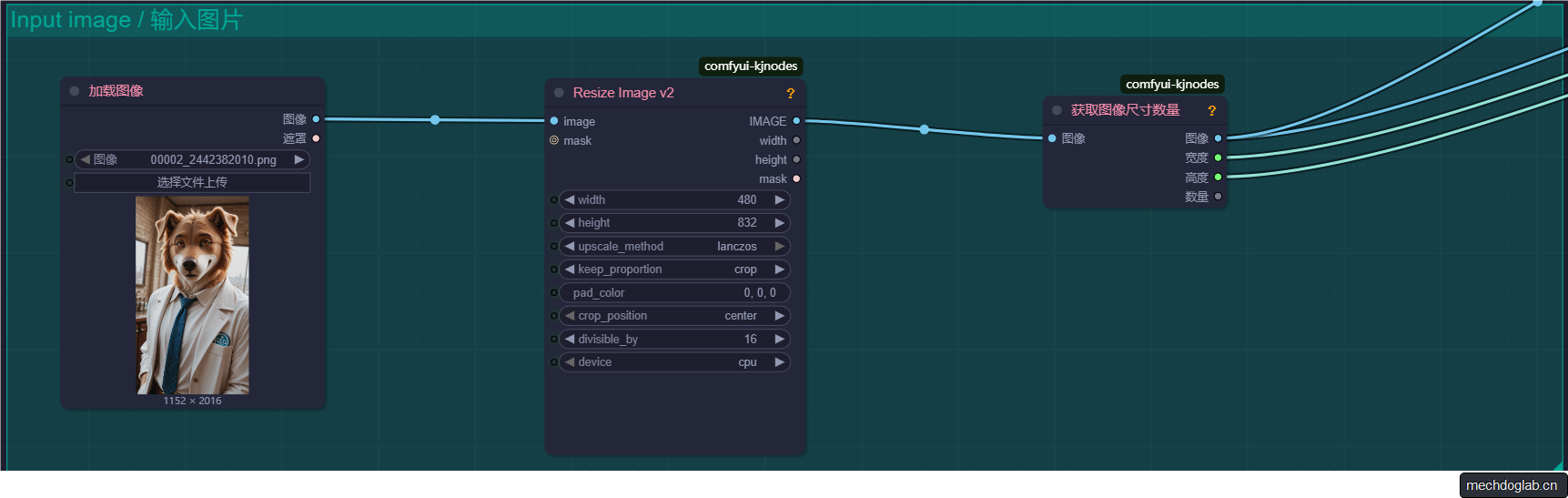
此处需要将视频缩放至符合视频模型的尺寸,采用剧中裁剪
音频处理
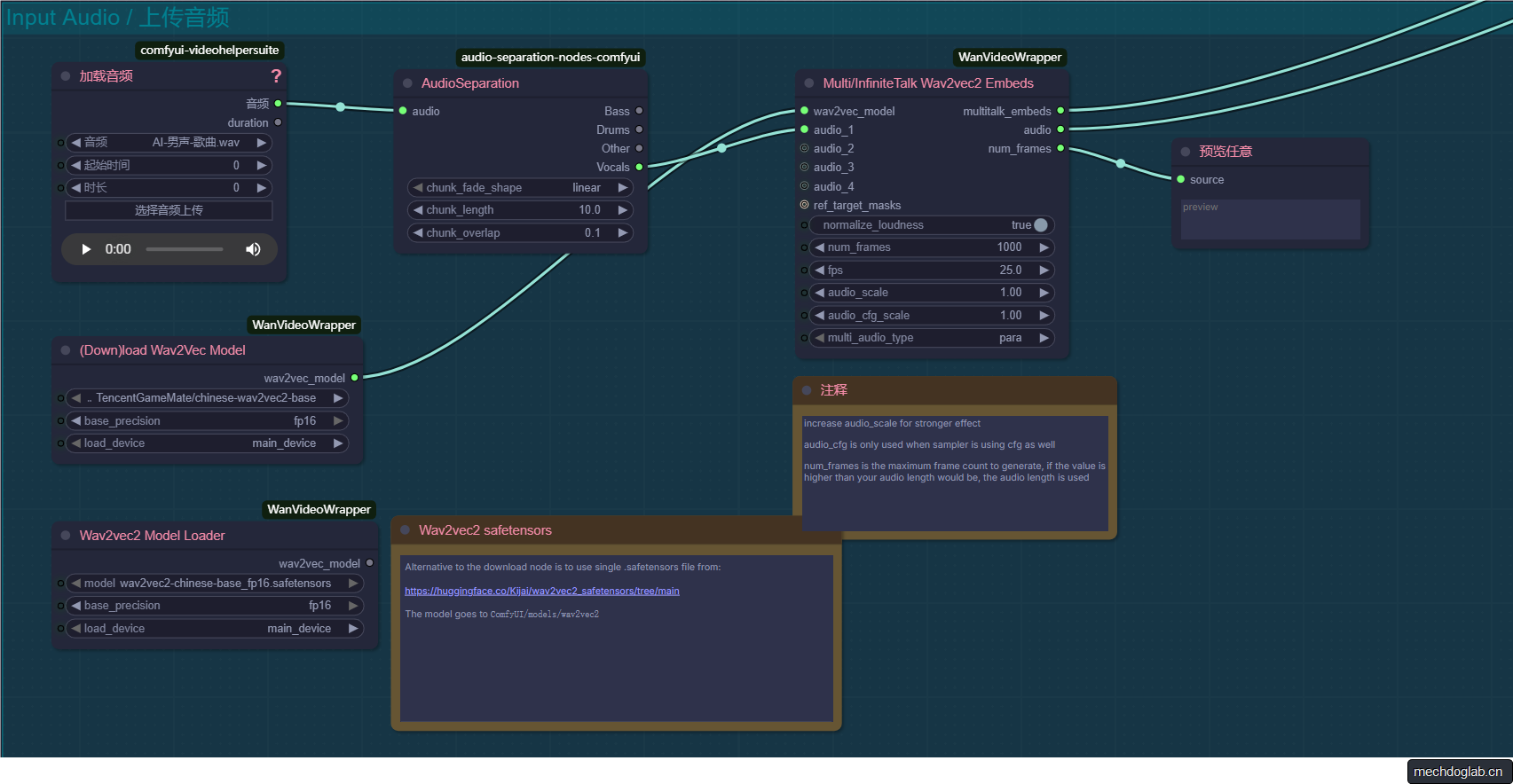
- (Down)load Wav2Vec Model节点会自动下载需要的模型
- 或者使用 Wav2vec2 Model Loader 读取本地模型
ComfyUI/models/wav2vec2 - AudioSeparation节点用于过滤非人生的部分
完整工作流
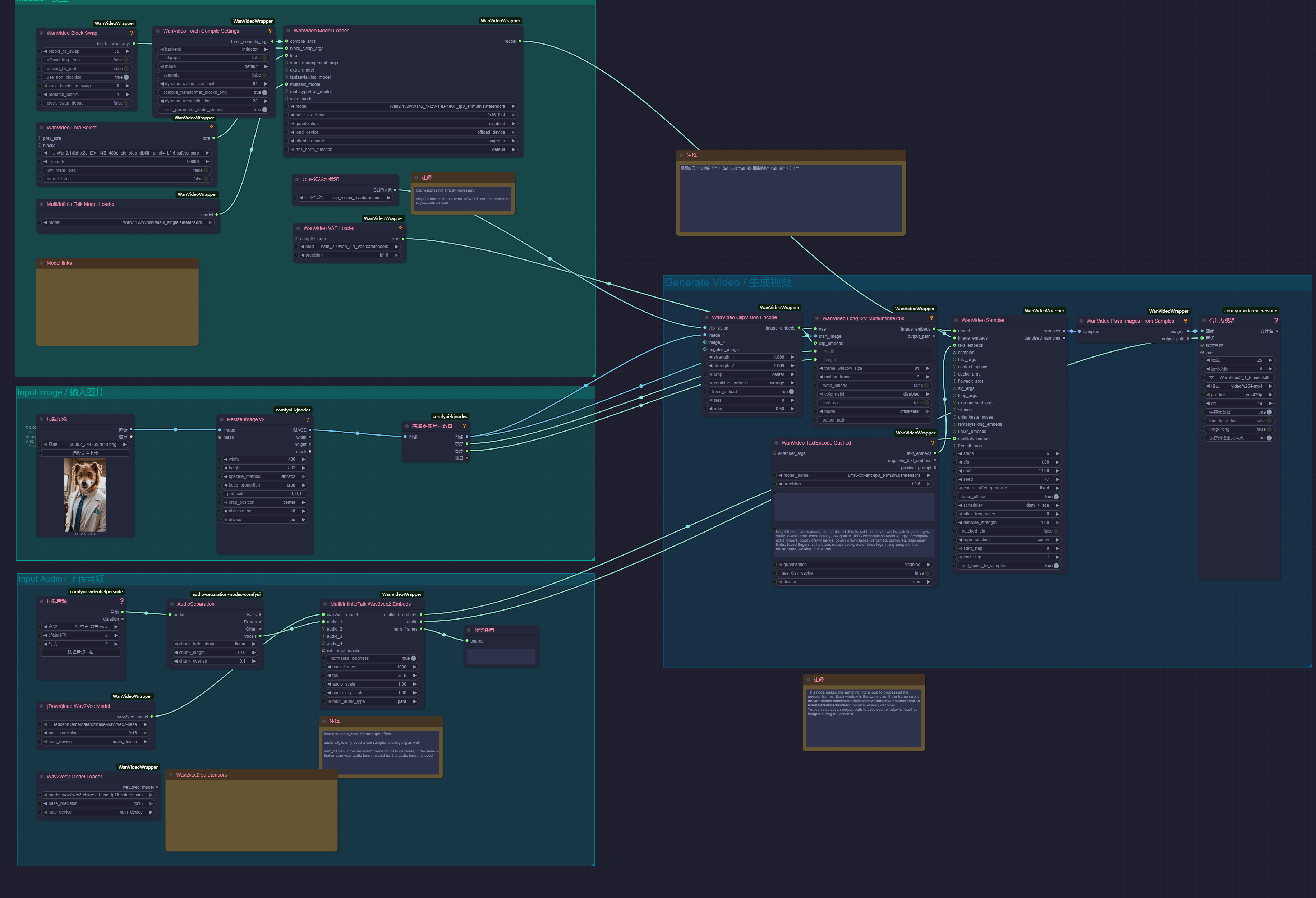
音频使用了开源的
ace_step_v1_3.5b.safetensors模型,和minimaxi.comAPI
效果演示_口播 视频文件托管在cloudflare
效果演示_唱歌 视频文件托管在cloudflare
评价
- InfiniteTalk对于Humo、Ovi、Sonic等在口型配合上有明显的进步,但是由于算法的锚点效应会在没有对话时回归到原图状态
- 对于无限生成来说,可以使用
视频时间 = 总帧数 /25 =(窗口大小*窗口数-重叠帧数*(窗口数-1))/25来计算匹配的音频长度 - 开源的
ace_step_v1_3.5b.safetensors对于短时间的歌曲创作效果不错,但是长时间会出现不符合要求的声音效果