ComfyUI支持文生图和图片编辑的模型——Qwen-Image-Edit-Rapid-AIO
- AICG
- 2025-11-04
- 10热度
- 0评论
模型基本信息
| 类别 | 内容 |
|---|---|
| 模型地址 | https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO |
| 核心功能 | Text-to-Image(文生图)、Image-to-Image(图生图,即图像编辑) |
| 适配工具 | ComfyUI(节点式AI图像工具) |
| 关联技术 | Qwen(通义千问系列模型)、Qwen-Edit(Qwen图像编辑能力) |
| 许可证 | Apache-2.0(开源许可证,允许商用且需保留版权信息) |
模型概述与核心特性
核心设计
该模型通过合并加速器(accelerators)、VAE(变分自编码器)和CLIP(对比语言-图像预训练模型) ,实现了便捷且快速的Qwen图像编辑功能,同时支持纯文生图任务。
内容安全版本区分
- v4及更早版本:将NSFW(不适合工作场景,含敏感内容)和SFW(适合工作场景,无敏感内容)功能整合在单个模型中,但性能表现一般(subpar)。
- v5及后续版本:将NSFW和SFW拆分为两个独立模型,可根据具体使用场景选择对应版本,专业性更强。
ComfyUI使用指南
基础节点配置
- 加载模型:使用「Load Checkpoint」(加载检查点)节点,选择模型文件(如
Qwen/Qwen-Rapid-AIO-v1.safetensors)。 - 核心参数设置:
- CFG值:1(控制文本对图像的引导强度,该模型推荐设为1)
- 采样步数:4(快速生成,模型优化适配4步流程)
- 精度模式:FP8(平衡速度与质量的浮点精度)
- 输入节点:使用「TextEncodeQwenImageEditPlus」节点:
- 可选输入1-4张图像(
image1~image3,无图像则触发纯文生图) - 需填入正向提示词(positive prompt),反向提示词(negative prompt,可留空)
- 关联CLIP模型和VAE模型(用于文本编码与图像解码)
常见问题解决(缩放/裁剪/缩放问题)
若遇到图像缩放、裁剪或变焦异常,问题根源通常是「TextEncodeQwenImageEditPlus」节点的原生缩放功能。推荐解决方案:
- 使用作者在「Files」(文件区)提供的自定义版本节点(支持最多4张输入图)。
- 配置
target_size(目标尺寸):设为略小于输出图像的最大边长(例如,输出1024×1024时,target_size设为896)。 - 优势:让输入图像分辨率更匹配输出分辨率,比完全跳过缩放步骤的图像质量更优。
模型版本历史(V1~V7)
| 版本 | 核心改进 | 推荐采样器(scheduler/solver) | 备注 |
|---|---|---|---|
| V1 | 基于Qwen-Image-Edit-2509和4步Lightning v2.0,含少量NSFW LORA | sa_solver/beta(推荐);euler_a/beta、er_sde/beta(可选) | 兼顾SFW与NSFW,通用性强 |
| V2 | 融合Qwen-Image-Edit加速器(支持8步与4步流程),优化NSFW LORA | sa_solver/simple(强烈推荐) | 提升多步数场景适应性,NSFW效果更均衡 |
| V3 | 采用新版Qwen-Image-Edit Lightning LORA,剔除劣质NSFW LORA、强化优质LORA | sa_solver/beta(高度推荐) | 图像质量显著提升 |
| V4 | 融合多个Qwen-Edit与基础Qwen加速器,新增皮肤修正LORA | 4-5步:sa_solver/simple、lcm/beta、euler_a/beta;6-8步:lcm/beta、euler_a/beta | 增强皮肤细节,适配不同步数需求 |
| V5 | 拆分SFW与NSFW独立模型;更新NSFW LORA(v5.2含snofs、qwen4play;v5.3加fok3827的Qwen Image NSFW Adv.) | SFW:lcm/beta、er_sde/beta;NSFW:lcm/normal | 解决两类场景相互干扰问题;提示词加“Professional digital photography”(专业数字摄影)可减少“塑料感” |
| V6 | 尝试以valiantcat/Qwen-Image-Edit-MeiTu和chestnutlzj/Edit-R1-Qwen-Image-Edit-2509为基础模型合并 | - | 合并失败(broken merge),推荐继续使用V5 |
| V7 | 将V6的两个基础模型作为LORA集成,微调加速器与NSFW LORA(v7.1更侧重NSFW) | 4-6步:lcm/sgm_uniform;7-8步:lcm/normal | 修复V6问题,性能稳定,是V5后的优选版本 |
推荐工作流参数示例
关键节点参数
| 节点名称 | 参数配置 |
|---|---|
| KSampler(采样器) | 种子(seed):65454653(固定);步数(steps):4;CFG:1.0;去噪(denoise):1.00;采样器:sa_solver;调度器:beta |
| TextEncodeQwenImageEditPlus | 正向提示词示例:“Put the woman holding a balloon next to the ninja in the hallway.”(让拿着气球的女人站在走廊里的忍者旁边);反向提示词:留空;输入图像:可选 |
| VAE Decode(VAE解码) | 输出分辨率:1024×1024 或 768×768 |
| Load Checkpoint | 批量大小(batch size):1;默认输出尺寸:768×768 |
输出尺寸建议
- 最终图像尺寸(Final Image Size):推荐768×768或1024×1024(需与
target_size适配) - latent(潜在空间)尺寸:与输出尺寸一致,确保图像无拉伸变形
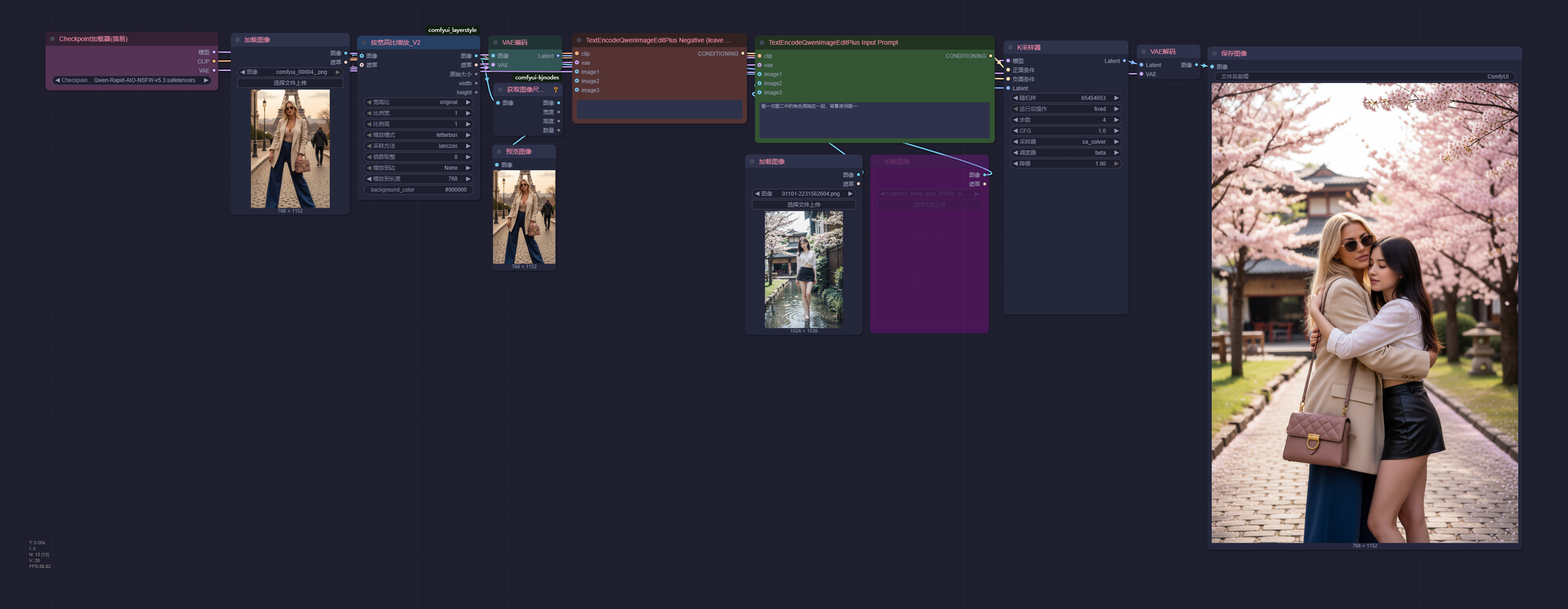
工作流演示——基础工作流
工作流演示——一致性生成N个同角色造型
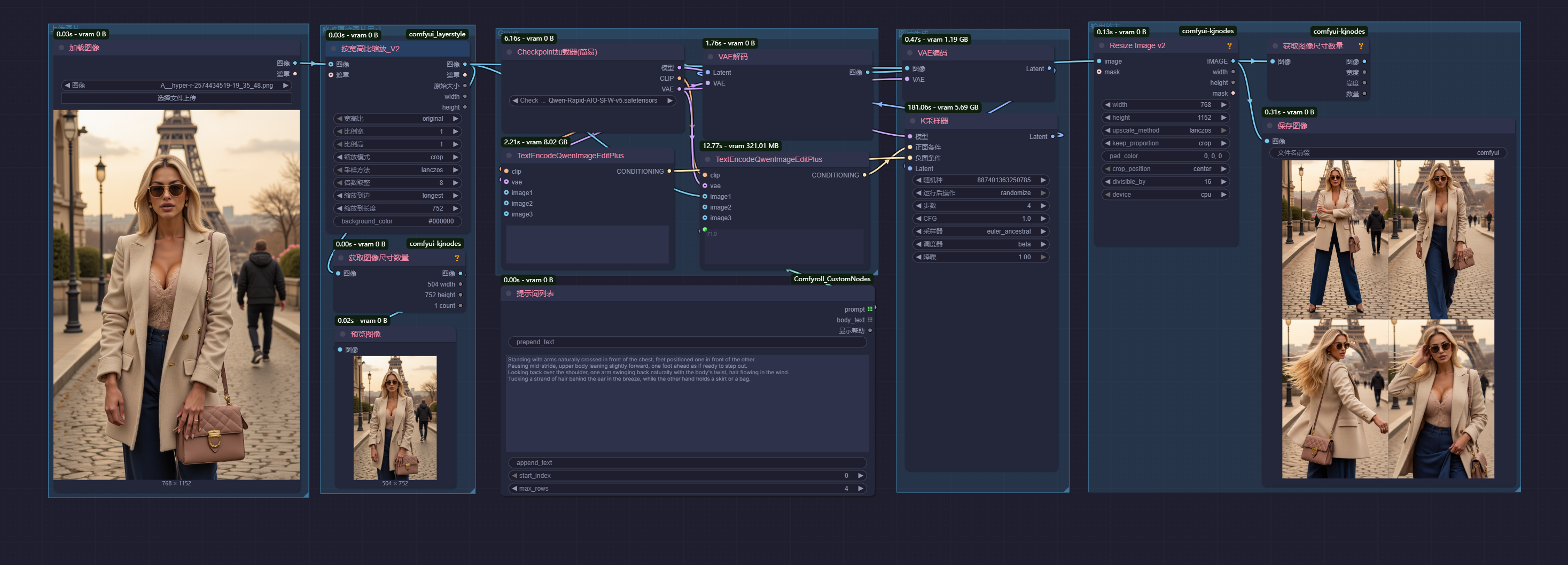
Standing with arms naturally crossed in front of the chest, feet positioned one in front of the other.
Pausing mid-stride, upper body leaning slightly forward, one foot ahead as if ready to step out.
Looking back over the shoulder, one arm swinging back naturally with the body's twist, hair flowing in the wind.
Tucking a strand of hair behind the ear in the breeze, while the other hand holds a skirt or a bag.
双臂自然交叉于胸前站立,双脚前后错开。
步履停驻,上身微倾向前,前足似欲迈步。
回头望去,随身体转动单臂自然后摆,发丝随风飘扬。
微风拂面时将发丝别于耳后,另一只手轻攥裙裾或提着包袋。根据原始工作流进行了微调
1.当显存容量较低时,可以降低分辨率和一次图片生成的次数
2.作者给的步数8,但是CFG降低到4也不会有明显影响
原工作流地址:https://www.runninghub.cn/workflow/1985615357727723522